奔跑在 K8S 上的 Tensorflow (三) 一些调优
本文介绍蘑菇街在分布式机器学习调优的一些经验,主要分为 K8S 层面,Tensorflow 层面和业务层面的一些调优。
K8S 层面调优
CPUShare VS CPUSet
以商品推荐常用的 wide and deep 模型为例,该模型采用 CPU 资源进行训练,宿主机的规格为 80C256G。
从直觉上说,训练本质上是大量的矩阵运算,而矩阵运算在内存地址空间具有良好的连续性。若充分利用 CPU cache,将有助于提升 cache 的命中率,最终加快训练速度。K8S 1.8 起支持 CPU Manager 特性,该特性支持对于 guarantee 类型的 pod,采用 cpuset 为 pod 分配专用的 CPU 核。在相同训练任务下对比 cpuset 和 cpushare 对训练速度的影响,发现在 worker CPU 核数较少的情况下,cpuset 的性能远远超过 cpushare。
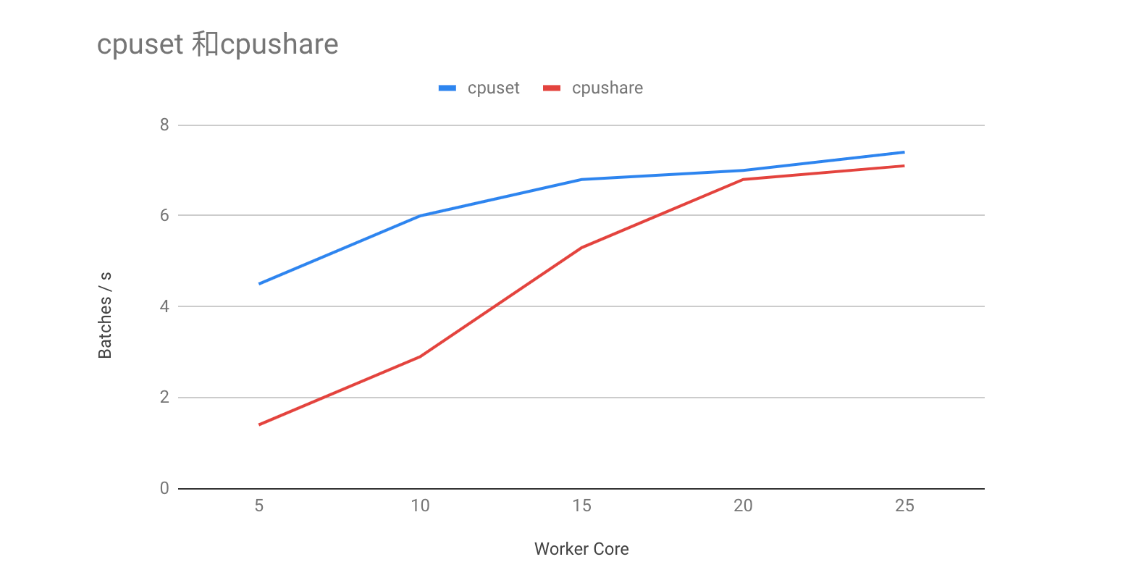
虽然 guarantee 类型的 pod 牺牲了资源弹性,但是 cpuset 带来的性能收益要高于弹性带来的收益。即使对 cpushare 容器不设置 cpu limits,当节点跑满容器时,相同 cpu requests 下,cpuset 容器的性能依旧比 cpushare 的性能高 20% 以上。
PodAffinity
PS-Worker 训练框架下,PS 节点作为中心节点,网络流量往往非常之大,容易把带宽跑满。通过 pod-affinity 将所有 PS 节点尽可能打散到不同的宿主机上,从而分摊网络流量。
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: tf-replica-type
operator: NotIn
values:
- ps
topologyKey: kubernetes.io/hostname
设置合适的资源配比
不同的模型的计算量和参数各不相同,因此针对每个模型都应该设置一个合适的 ps/worker 的规格和数量。在监控完善的条件下,可以根据监控数据分析瓶颈,调整实例的规格和数量,使得整体的训练速度和平台吞吐量能达到较好的水平。
Tensorflow 层面调优
Tensorflow 的调优主要参考官网文档 Performance。
线程数
由于 sysconf 系统调用等隔离性的问题,容器看的 CPU 往往是宿主机的 CPU 核数。tensorflow 默认的线程数为 CPU 核数,如此情况下,tensorflow 创建的线程数远远超过实际分配到的 CPU 核数。同样以 wide and deep 模型为例,通过保持与 cpu limit 一致的线程数,上下文切换降低约 40%,训练速度提升约 5%。
config = tf.ConfigProto()
config.intra_op_parallelism_threads = cpu_limit_cores
config.inter_op_parallelism_threads = cpu_limit_cores
tf.Session(config=config)
Intel MKL
之所以谈谈 Intel MKL,是因为编译 MKL tensorflow 后,测试发现 MKL 并没有带来明显的性能提升……
业务层面调优
Partition
发现 PS 流量节点分布不均匀,其中某个 PS 节点的流量非常大,而其它 PS 节点的流量相对较低。通过 timeline.json 发现,主要是某个 embedding 向量非常之大,所以通过 partion,将该 tensor 分散到不同的 PS 节点上,避免某个 PS 节点瓶颈。
partitioner = tf.fixed_size_partitioner(ps_number, axis=0)
with tf.variable_scope("emb_layer", partitioner= partitioner) as scope:
...
Adam 优化器
由于 Adam 优化器会更新所有参数的梯度,所以在大 embedding 向量下,如果采用 adam 优化器,会大大增加计算量,严重影响训练速度。因此建议采用 Lazy_Adam_Optimizer 或者 Adadelta 优化器。
TBD…