[首发于 InfoQ]蘑菇街机器学习标注平台实践
数据标注行业流淌这么一句话:“有多少智能,就有多少人工”。大量的训练数据是进行深度学习的前提,数据的质量决定了模型的上限,而训练数据产生离不开数据标注,数据标注作为机器学习工程中重要的一环,是构建 AI 金字塔的基础。以旷世科技 AI 独角兽为例,它的标注员工多达 405 人,占公司员工比例的 17.2 %
在许多学术界和工业界人士努力下,先后在多个领域诞生了开放数据集,从入门的 MNIST,再到大名鼎鼎的 Image Net,涵盖了通用场景。但在实际的业务通常碰到某些细分领域没有开放数据集,比如服装的类型和风格,这就要求自己构建训练数据集,或自力更生,或临时雇用外包人员(自己提供工具),甚至全权委托给专业标注公司(无需提供标注工具,成本高)。蘑菇街有大量数据标注的需求,综合成本、效率等因素考虑,我们建设了统一的标注平台,支撑众多的标注业务,部分样图请见如下。
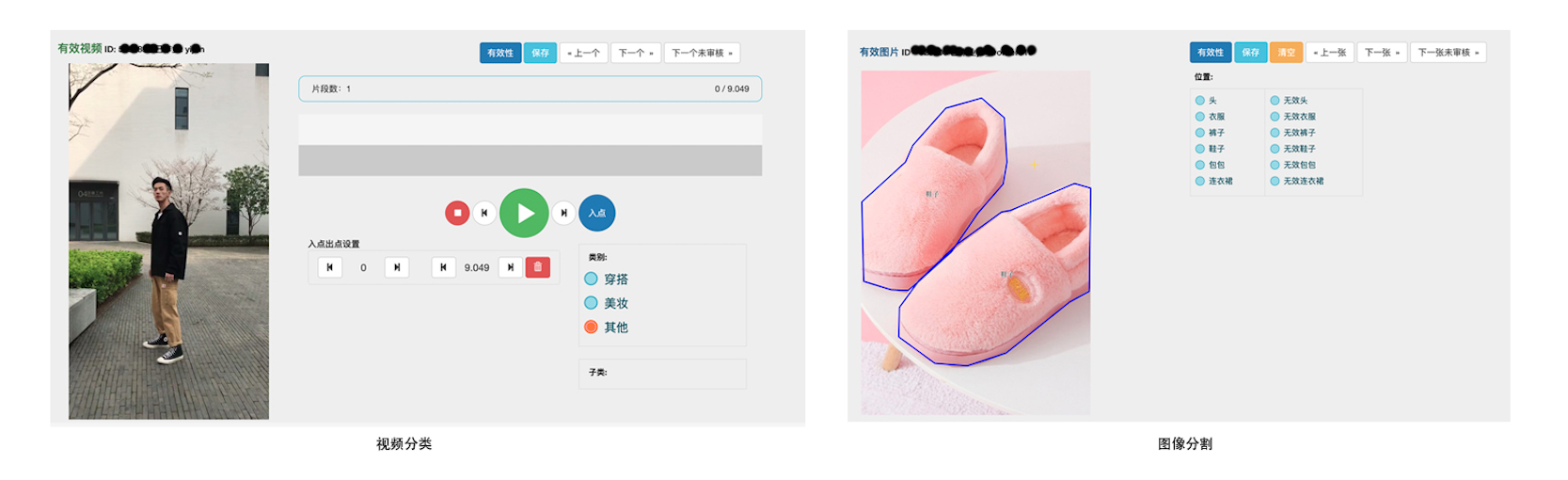
常见的标注场景
从领域角度,蘑菇街的机器学习业务可分为 CTR(点击通过率)、计算视觉和 NLP 三类,其中 CTR 为排序推荐相关业务,这类业务通过埋点收集数据。对于大部分计算视觉和 NLP 的训练任务,需要标注构建数据集。
不仅于蘑菇街,放眼业界,常见的标注场景可以分为如下两大类(音频的场景相对较少,不在讨论范围内):
- 计算视觉
- 分类:对图片和视频进行分类,例如服装颜色、类型分类等。
- 分割:对图片进行分割,比如从交通图像分割出道路,从服装图像分割出裤子、上衣等。
-
目标检测:通常采用矩形框圈出目标物体,并贴上标签,比如圈出服装图像中的鞋子,交通图像中的汽车。
-
NLP
- 分类:对文本进行分类,比如情感分类。
- 实体识别:从文本提取出具有特定意义的实体,比如从商品描述中标注商品名称,描述商品的形容词等。
- 翻译:不同语言之间的转换,如英译中。
开源的标注工具
Github 诞生了许多开源的标注工具,涵盖了计算视觉、NLP 等诸多领域,特别在计算视觉方面,许多优秀的开源项目如雨后春笋一般,其中不乏有如 OpenCV 社区和 Microsoft 等商业公司的支持。笔者梳理了部分计算视觉、NLP 等领域部分人气较好的标注项目,如下表所示。
| 项目 | 适合场景 | 说明 | 桌面/Web | stars |
|---|---|---|---|---|
| labelImg | 目标检测(图像) | 采用矩形框标注目标,结果保存至本地 xml 文件 | 桌面软件 | 8.8K |
| cvat | 目标检测、分割、分类任务(图像和视频) | 功能强大,支持图像和视频的多种标准场景,支持导出多种格式结果文件 | Django Web 服务 | 2.6K |
| labelme | 目标检测、分割、分类任务(图像) | 功能较为强大 | 桌面软件 | 3.5K |
| vatic | 目标检测、目标跟踪(视频) | 面向视频的目标检测和目标跟踪,结果保存至 DB 中 | Web 服务 | 0.4K |
| doccano | NLP 命名实体识别、文本分类、翻译任务 | 功能强大,支持多种语言,支持用户管理,结果保存至 SQL DB 中 | Django Web 服务 | 1.9K |
| Chinese-Annotator | NLP 命名实体识别、文本分类、关系提取 | 面向中文的智能文本标注,结果保存至 Mongo DB 中 | Django Web 服务 | 0.9 K |
| audio-annotator | 音频分类标注 | 面向音频片段的分类标注 | Web 服务 | 0.2K |
这些优秀的开源项目专注于细分的领域,适合通用场景下的标注,用户经安装和配置即可开展标注工作,有些还甚至支持生成训练样本,这对于规模较小,算法业务较为单一的团队很适合。但是对于算法业务复杂,数据量大,场景特殊的公司而言,直接基于上述工具可能会带来巨大的维护和管理成本。
1) 服务管理:在多人(特别是异地外包)标注下,采用桌面工具会带来大量部署和维护的问题,同时涉及大量数据分发和分配问题,繁杂且容易引入错误。所以标注服务最好应该提供统一的 Web 入口,标注人员无论身处何处,采用何种操作系统,仅需登录 web 界面即可开展工作;对研发人员而言,维护一个统一的前后端服务的工作量远远低于维护多个标注工具。
2) 数据管理:有些工具将数据保存到本地 xml,有些保存到 MySQL 或者 NoSQL,不同项目的数据格式也存在很大差异,带来较高的管理成本和隐患。因此数据应该采用统一的高可靠存储,不仅可以精简维护成本,而且利于衔接样本构建模块。
3) 用户管理:用户和权限管理是多人标注下的一个重要需求,也是大部分标注工具缺失的功能。它在保证安全的同时,还记录了数据的标注者和审核者,便于追溯和结算。
由此可知对于标注业务繁多的团队,很有必要构建统一的标注平台,从而规范流程和风格,对外提供简单易用的服务,支持多人标注,降低维护成本;同时把数据存储集中化,数据结构标准化,为下游的样本生成模块奠定良好的基础。
蘑菇街标注平台的设计
本节重点谈谈蘑菇街标注平台的设计,我们的目标就是构建一个统一、扩展性强、易用的 Web 标注平台,支持员工、外包等的标注和审核工作。
设计要点
面向流程 vs 面向业务
我们起初试图围绕业务进行抽象,期望为前后端提供一个统一的框架,深度调研发现不同的标注场景,其前端技术栈和实现,数据结构存在巨大的差异,抽象难度高,可行性低。但是从流程的角度出发,所有标注任务的流程非常相似,可梳理成如下:
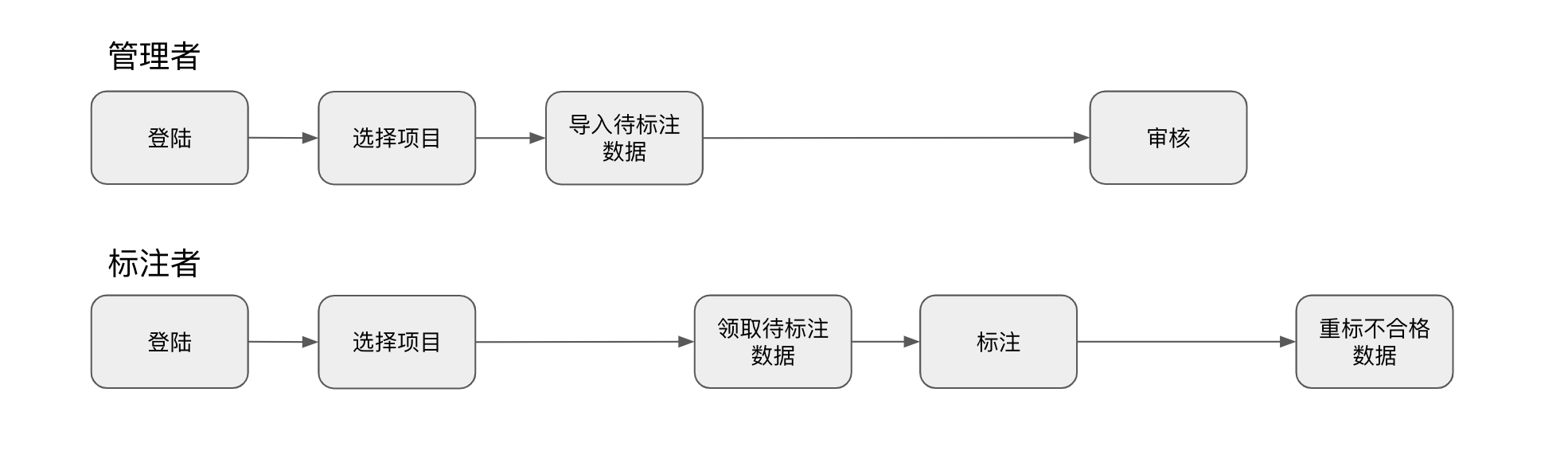
我们所有标注业务都遵循上述流程,其中部分流程完全一样,共用一套代码逻辑即可,差异部分的流程由每个标注业务自己实现,且互相独立,例如导入待数据过程中对数据的解析,标注和审核页面的实现等等。故每接入一个新标注业务,只需实现数据解析、标注和审核页面相关逻辑即可。特别对于前端页面,由于标注业务之间互相独立,可各自按需选择前端框架,同时方便从开源的项目中移植相关代码,具备良好的可扩展性。
数据管理
标注数据可分为图片、视频、NLP 文本、元数据(包括标注结果)等等,其中图片和视频占据较大的存储空间,上千万张图片占达着数 TB 的存储空间,相比本地存储,采用云服务的对象存储是更好的选择。对于 NLP 文本、标注结果及元数据等,具有占用空间少、结构化强的特点,适合存储在数据库中。
具体实现
框架选型
绝大部分开源的 Web 标注工具均基于 Django 实现,采用 Python Django 利于开源项目的移植;此外算法同学对 Python 的掌握好于其它语言,如此便于算法同学参与部分逻辑开发,比如数据的解析等等。
每当接入一个新的标注项目,采用如下命令即可创建一个 Django 应用,在对应目录下实现差异化的流程即可。
python manage.py startapp {mark_app}
以蘑菇街的标注平台为例,这些差异化的流程体现在如下方面:
- 解析导入的待标注数据文件:不同标注任务其原始数据差异较大,比如图像通常图片在 CDN 上的 URL,NLP 则为文本文字,故需要实现特定的解析逻辑。
- 标注结果序列化和反序列化:不同标注任务其标注结果存在较大差异,写入和读取 DB 时需要实现序列化和反序列化。
- 标注和审核 Web 页面:不同标注任务的页面差异较大,可选取合适的前端框架进行实现。
数据管理
我们把图像和视频全部存储于云服务中的对象存储,由对象存储保证高可靠性,每个图片和视频都有全局唯一的 URL,故导入待标注数据时只需导入 URL。在标注和审核过程中,前端根据 URL 从 CDN 下载数据并展示,便捷而高效。
元数据存储于 MySQL 中,主要有两张表,一张为用户相关的表,用于用户和权限的管理。另外一张为标注相关的表,记录了某条数据的基本信息,包括原始数据(data)、标注结果(label)、标注者、审核者、状态和所属项目等信息,几个重点的 column 如下:
`id` INT(11)
`data` MEDIUMTEXT # 图像视频的 URL,NLP 文本,或者图片和文本的混合
`label` MEDIUMTEXT # 标注结果,一般为 json 格式,便于序列化和反序列化
`project` VARCHAR(60) # 对应的标注项目
`importuser` VARCHAR(60) # 待标注数据导入者
`markuser` VARCHAR(60) # 标注者
`checkuser` VARCHAR(60) # 审核者
... # 其它如时间、状态等信息
不同标注业务的 data 字段和 label 字段内容差异很大,data 一般为图像视频的 URL,NLP 的文本文字,或者图像和文本的结合体;label 字段的差异就更大,分类项目的数据结构往往很简单,而分割类项目的数据结构则复杂许多。所以我们把 data 和 label 两个字段设置为 text,数据结构的定义和数据的序列化、反序列化在各自的项目中实现,大大的提升了可扩展性。由于所有的标注数据均共用这张表,避免为每个项目都维护一张数据表,降低了接入和维护成本。
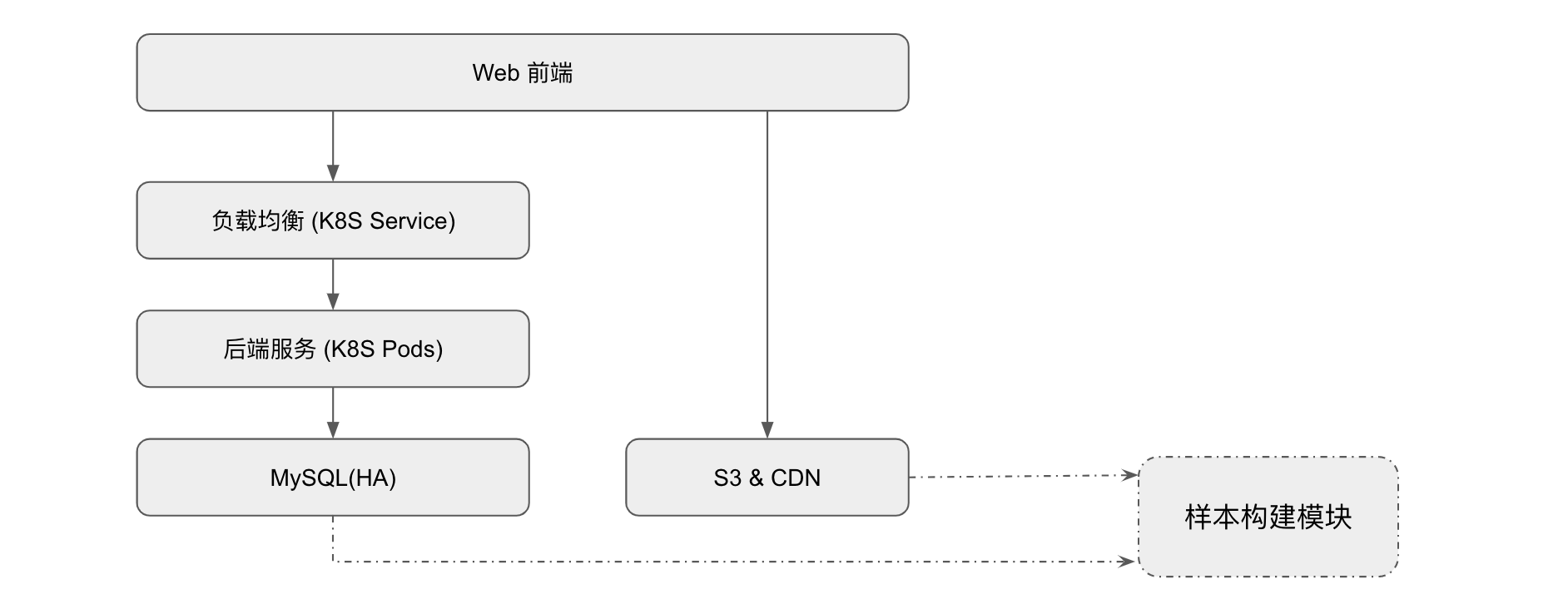
部署架构
标注平台的架构比较简单,数据存储在 MySQL 和对象存储中,服务部署在 K8S 的 statefulset 中,由 statefulset 保证高可靠。用户访问 K8S 的 Service,再由 Service 将负载均衡转发至 Pod。
顺带提下样本构建模块,它从 MySQL 获取基本数据,并从 CDN 中下载对应的图片或视频,最终生成如 TFRecords 等格式的训练样本。
高级特性和展望
为了保证数据质量,算法同学通常会承担一定的审核工作。但是由于标注的数据量实在太大,即使采用 10% 的抽查率,每个项目往往需要审核数万条数据。对于部分标注项目,我们的平台支持采用早批次的数据训练出模型,初步审查后续的标注结果,对于异常值,再由人工进行第二轮审核,提升审核效率。
在图像分割和 NLP 领域,部分开源的标注工具包含了智能算法,辅助人员进行标注,以提升标注效率,本人认为这是未来标注项目的一个趋势,特别对于标注成本较高,数据量比较大的项目,可以考虑采用智能辅助标注降低成本,提升效率。