深度学习系统 101 黑板报
Overview
基于数据并行的分布式深度学习在前几年已成为主流实践,一个训练的 step 分为两部分:
- 计算(T1):worker 完成 forward propagation 和 back propagation 后得到梯度。
- 梯度规约(T2):汇总所有 worker 梯度进行优化器计算,并将结果同步到所有的 worker,本质上是分布式通讯的问题。
本文主要探讨如下命题。
给定“业务模型、网络拓扑、异构和弹性资源”等约束下,如何系统性的优化工程架构,获取 Max(AUC, Real resource usage)。
业务模型
CV/NLP 等通用场景和推广搜场景的模型差异很大,基本决定训练的拓扑和资源类型。
- 通用场景:神经网络参数多,计算量大,通常采用 GPU 计算,单卡显存可以容纳整个模型。一般采用 All-Reduce 拓扑,同步训练。
- 推广搜:神经网络参数少,计算量小,通常采用 CPU 计算,Embedding Table 依赖分布式参数服务器 PS。故采用 PS-Worker 拓扑,异步训练。
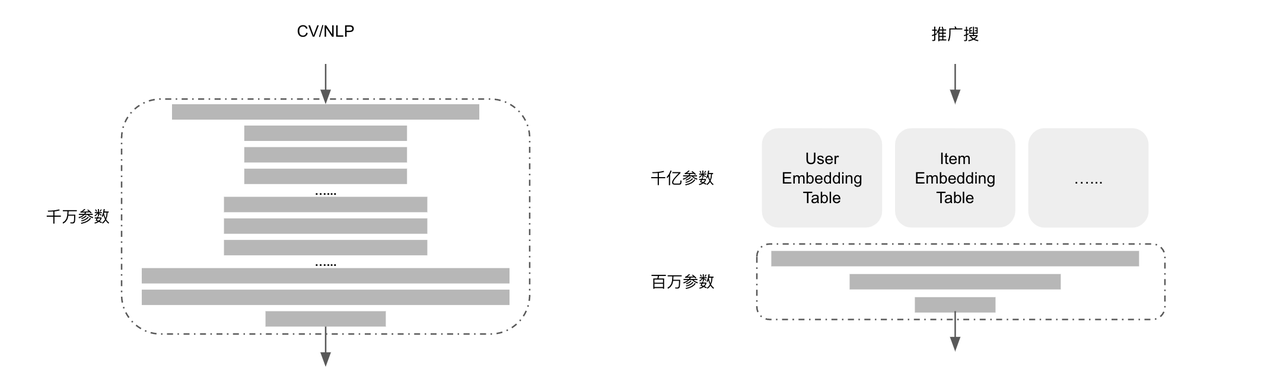
通用场景
CV/NLP/Speech 是常见的通用场景,Worker 存储完整的模型。MPI AllReduce 语义刚好完美的支持梯度规约的操作,大部分框架采用 MPI 接口实现梯度规约。特点如下:
- Worker 理论上具备故障容忍和弹性能力;木桶效应强烈;网络带宽大。 如此给系统工程带来编排、调度、框架层面优化一系列需求:
- Worker 资源必须同质化(相同 GPU)
- Worker 必须考虑网络拓扑的亲和性,可以从单机、IDC 拓扑联动 AllReduce 优化具体实现。
- Worker 故障/扩缩需要让相关 Worker 感知和更新通讯拓扑,否则整个任务失败
- 业务、框架、编排调度需要协调增加对弹性资源的支持
- 框架可以通过编码等方式优化通讯带宽,通过 pipeline 提升训练吞吐
- ……
##推广搜
Deep-Wide 是“推广搜”主流模型,亿级别用户和亿级别 item(视频、商品)巨大特征表决定必须采用 PS-Worker 框架,其中 PS 存储 Embedding 和神经网络,worker 存储神经网络。特点如下:
- PS: 单个异常会导致整个任务的失败;木桶效应强烈;网络带宽大。
- Worker:单个异常不影响任务,可以弹性伸缩,慢 worker 的梯度会被丢弃。
如此给系统工程带来编排、调度、框架层面优化一系列需求:
- PS 必须保证高优资源
- 微拓扑绑核保证 PS 的稳定性,避免受干扰
- 框架必须保证模型在 PS 均衡 partition,避免热点问题
- PS 资源尽量同质化,例如相同的机型(CPU 型号)
- PS 和 Worker 必须考虑网络拓扑的亲和性
- Worker 可使用弹性资源
- 框架可以通过编码等方式优化通讯带宽,通过 pipeline 提升训练吞吐
- 框架大大提升从 PS 异步拉取参数的频率,降低慢 worker 梯度被丢弃概率
- ……
框架浅谈
面对层出不穷的 ML 相关名词,本文根据层次做了如下梳理。
正如贾扬清大神所言,单纯再造深度计算框架意义很小,Pytorch/Tensorflow 无可比拟的学术和工业生态已成为深度计算框架的当代双雄,对此本文不再论述。为了优化性能和 AUC,工业界结合业务模型和物理环境在分布式框架领域做细分方向的创新。
梯度规约时间占比越大,分布式(通讯)框架优化的价值越高
- 工程拓扑:网络拓扑与通讯拓扑、弹性和容错能力
- 通讯优化:信息压缩、ops 通讯合并、分桶、训练和通讯 pipeline
AllReduce 实现非常之多,是论文频繁出之地。从 2017 年百度将 MPI 领域 RingAllReduce 引入到深度学习后,便成为主流的分布式通讯算法。正如其论文所述:
in fact, if you only consider bandwidth as a factor in your communication cost (and ignore latency), the ring allreduce is an optimal communication algorithm
因此 Pytorch/Tensorflow/Horovod/PaddlePaddle 均采用 RingAllReduce 作为其分布式通讯算法。其中 Horovod 优异的工程实现和良好的体验,封装常见 AllReduce 底层网络通信(OpenMPI, Gloo, NCCL),支持多种深度学习框架而颇受欢迎。
BytePS 更像是同步的 PS-Worker 架构,引入廉价的额外 CPU PS 节点增加辅助带宽,理论效果等同 RingAllReduce 单机增加一张网卡,但是却引入更复杂的技术设计,故障容忍上也带来更大的挑战。值得一提的是 BytePS 充分利用单机 NVLink 微拓扑优化通讯,形式上类似采用 Hierarchy AllReduce。
演进思考:
- 大力出奇迹,深度大模型超出单卡显存上线需要模型并行,或带来新分布式框架的创新和编排调度需求。
- 分布式框架的通讯效率需要结合物理拓扑和编排调度进行优化,需要增加对弹性能力的支持。
- 分布式框架结合信息相关理论,ops 合并、均衡 partition 优化通讯效率。
- 抽象更强大的数据编排能力,支持丰富的框架和更多的业务场景。
- 数据处理层面或可以抽象统一的数据编排框架,支持多种深度学习框架,支持丰富的数据源,支持丰富的数据处理、编排语义,支持数据加速、弹性等场景。
- 流批一体
基础设施
硬件能力
回顾过去十年,单位价格 CPU 算力增长 10 倍左右、网络带宽增长约 100 倍。
网络基础能力:
- 单机:
- GPU NVLink 提供机内高效通讯能力。
- 单机网络带宽随着显卡类型迅速增加:V100 100Gb -> A100 200Gb * 4
- 机房:接入和汇聚交换机的能力不断增强,收敛比不断提升。
演进思考 :
- 分布式训练主要为东西向通讯,故单集群控制在 BigPod 维度。
- 鉴于微服务网络带宽低,主体往集群内融合调度而非集群之间出让的方式演进,即 Google Borg。
- AllReduce 通讯拓扑深度结合单机和 IDC 网络拓扑(甚至联动 P4 交换机),编排调度需要提供丰富的拓扑编排语义。
- 软硬协同:K8S 支持更丰富的异构的深度学习硬件等。
##弹性能力
为了充分利用微服务丰富的弹性资源,离线应用业务、训练框架和编排调度需要系统性的设计,在提升容错能力的基础上充分利于弹性资源。在 Worker 异常和弹性扩缩的场景下:
- 应用业务层:动态调整数据的 partition、learning rate、save state(清理)/checkpoint、prestop 等。
- 训练框架层:服务发现、更新通讯拓扑、故障容忍等、适配调度层的弹性能力。
- 编排调度层:调度和 QoS(角色)、弹性基础能力和策略、周边的基础设施。
演进思考:
- 平台:特别是通用的机器学习平台层面,需要丰富弹性的入口。
- 分布式框架层:框架等增强对容错、弹性能力支持,如 BytePS(支持主动弹性,不支持容错)、Horovod(支持弹性和容错),提供低开销级的 save/restore 能力。针对应用业务层需要感知的变更抽象易用的函数、最佳实践等。