Twine: A Unified Cluster Management System for Shared Infrastructure 阅读笔记
Twine 是在充满众多“烟筒”下艰难形成的,携带着深厚的历史和业务定制包袱,因而侧重在“下层”如硬件与运维体系解决资源(集群)管理、容灾的能力。个人的感受是理论基础不够扎实(移动 job vs 移动机器)、架构庞杂、缺乏单机层面隔离、资源利用率效果上不如 Borg,生态上偏离主流;但是在机器流转和定制方面有一定的借鉴之处。
截至论发表时,Twine 已经支持 Frontend / ML / Backend / Streaming / Stateful Service 等业务(不支持持久化存储)。下图是 Twine 的成长历史,本人认为大致可以分为三个阶段:
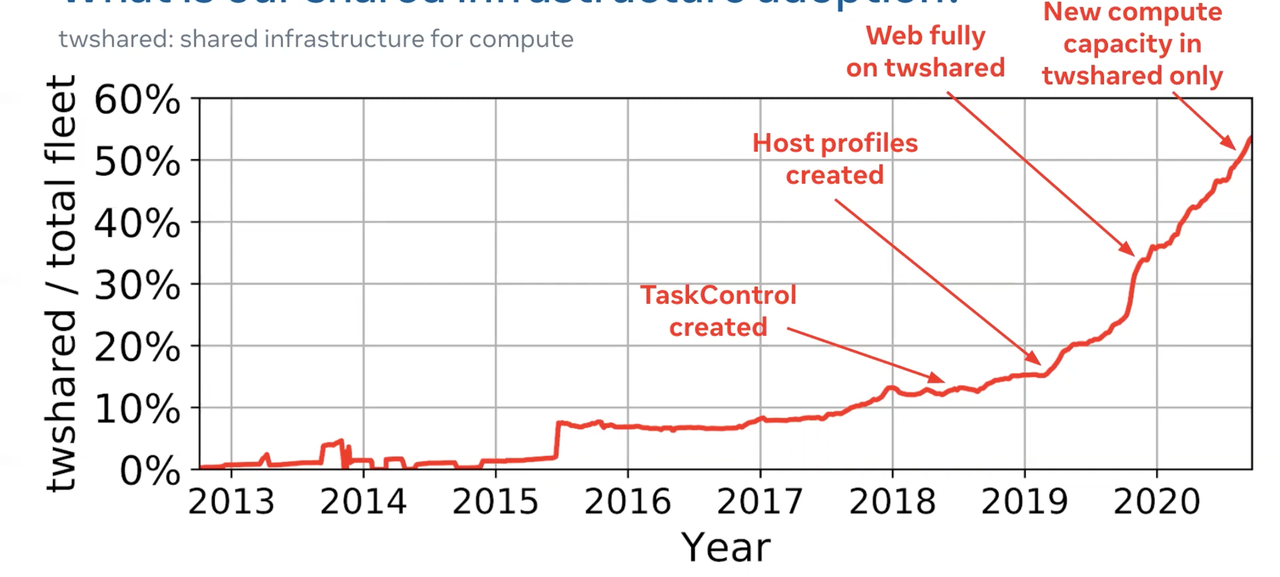
- 2013-2015:艰难前行,几经胎死腹中。
- 2015-2018:可能获得某些个大客户的支持,迅速上量到 8%,经历近 3 年的迭代和打磨。而有趣的是,2015 年推出 Kubernetes 大行其道,Twine 竟然坚强的挺过来了。
- 2018-至今:上线 TaskControl(类似 K8S CRD/Operator)、Host Profile 等对各类业务更灵活的支持,托管最核心的在线服务后,快速的起量并一举占据半壁资源。
Introduction
Existing systems, however, still have limitations in supporting large-scale shared infrastructure
- They usually focus on isolated clusters, with limited support for cross-cluster management as an afterthought.
- They rarely consult an application about its lifecycle management operations.
- They rarely allow an application to provide its preferred custom hardware and OS settings to shared machines.
- They usually prefer big machines with more CPUs and memory in order to stack workloads and increase utilization.
上述是 Twine 造轮子的原因,其中 1 和 3 有一定的道理;而 2 和 4 不太站得住脚,比如 K8S 的 Operator 支持灵活自定义的任务编排能力;且硬件上总体是往大规格不断发展的。而如下更像是 Twine 形成的原因:
- Infrastructure management is disaggregated, each BU and even team own their own private pools.
- 2/8 effect, the top 50 services consume 70% resource and have various customization requirements.
Twine packages applications into Linux containers and manages the lifecycle of machines, containers, and applications. A task is one instance of an application deployed in a container, and a job is a group of tasks of the same application.
和大部分集群管理系统一样,对任务的抽象上分为 job 和 task。
Twine 自称特色如下:
- A single control plane to manage one million machines
吐槽点:Although none of our regions host one million machines yet, we are close and anticipate reaching that scale in the near future
- Collaborative lifecycle management
- Host-level customization
Host profile,定制硬件和内核参数,具有一定的场景。
- Power-efficient machines
- Shared infrastructure.
Shared 的粒度为 Machine 级别,客观上统一资源池,优化了 Buffer,加速资源流转;不过粒度上存在很大优化空间。
Twine Design and Implementation
The Capacity Portal allows users to request or modify entitlements, which associate capacity quotas with business units defined in the service. With a granted entitlement, a user deploys jobs through the front end. The scheduler manages job and task lifecycle. If a job has a TaskController, the scheduler coordinates with the TaskController to make decisions. The allocator assigns machines to entitlements and assigns tasks to machines. ReBalancer runs asynchronously and continuously to improve the allocator’s decisions. Resource Broker (RB) stores machine information and unavailability events that track hardware failures and planned maintenance. The Health Check Service (HCS) monitors machines and updates their status in RB. The agent runs on every machine to manage tasks. Sidekick switches host profiles as needed. Service Resource Manager (SRM) autoscales jobs in response to load changes. Conveyor is our continuous delivery system.
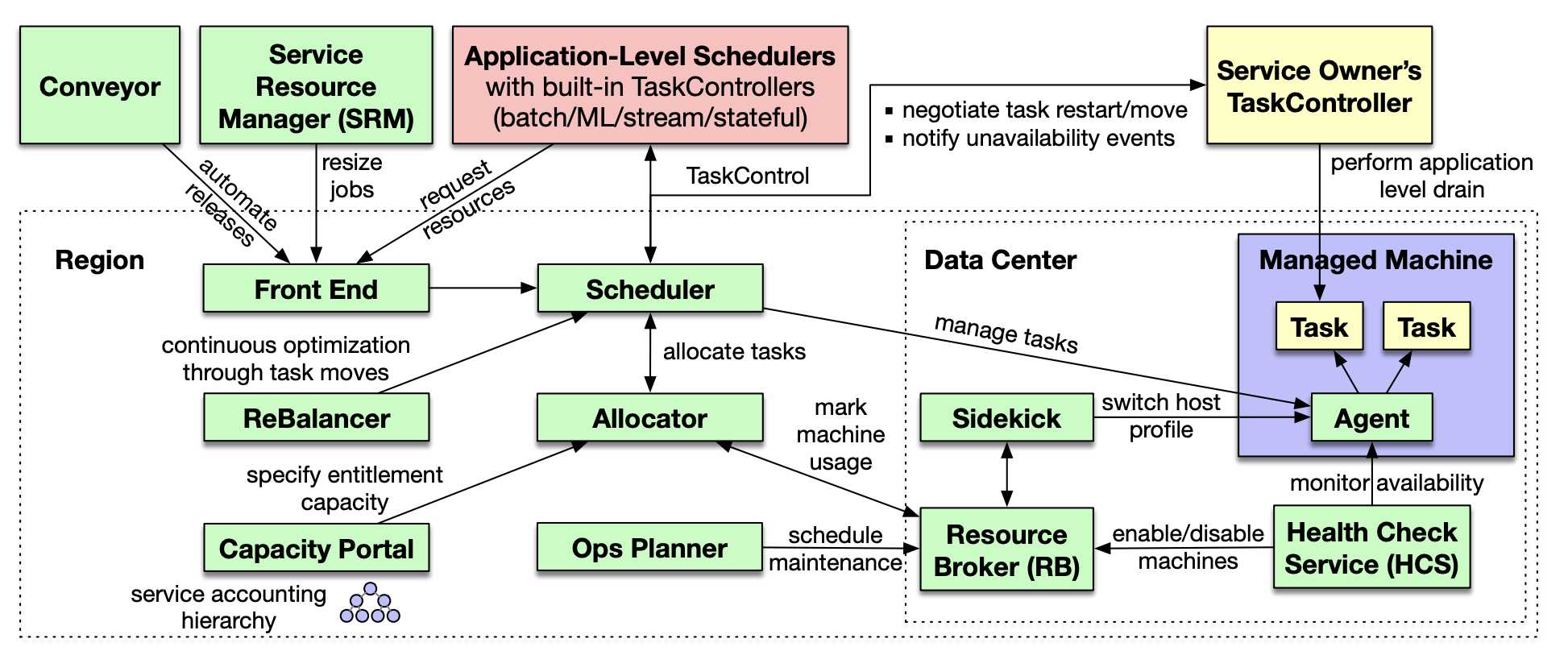
相比论文的架构图,私认为更易于理解的架构图如下:

Twine 是一个 Region 级别的集群管理系统,某种意义上更像 K8S 的 Cluster API,同时具备基础的调度和编排能力:
- 用户可以申请集群(Entitlement),同一个集群下的机器通常是同类型的,Twine 为此集群动态的分配机器。
- 提供基本的任务抽象和生命周期管理能力,允许用户在其集群中自定义生命周期管理的逻辑。
- 提供基础的粗粒度调度能力,即根据用户诉求将机器分配给集群;允许用户在其集群中扩展调度器,比如 Batch Scheduler。
类比 K8S,本人认为 Allocator 更像是一个调度器,它接受申请机器的请求并且根据约束条件将机器分配到合适的集群上;Rebalancer 更像是 Rescheduler / Descheduler;Service Resource Manager 更像是 HPA。
Twine Scheduler 其实更像是一个任务的生命周期管控模块,可类比 K8S Controller。它根据任务状态、硬件状态、业务约束等输入管控其生命周期,并联动服务发现,从而应对异常可提供高可靠的能力。
Task Controller 更像是 Kubernetes 的 Operator,允许用户定义符合业务要求的编排能力,从而为 Twine 托管各类业务奠定基础。Application-Level Scheduler 允许业务自定义调度能力,Facebook 中的有状态服务、批式计算、流式处理、机器学习和视频处理均有业务自定义的调度器;以 Batch Scheduler 为例,用户从 Twine 申请集群批发一大比资源后,job/task 和节点的匹配关系完全交由业务的 Batch Scheduler 进行调度,Twine 的 Scheduler / Allocator 对此并不感知。
Scability & Availability
关于 Scability,Twine 的核心理念是 Sharding,并且以 entitlements 作为主要 sharding 对象。
关于 Availability,其设计原则为:
- All components are sharded
- All components are replicated
- Tasks keep running
- Rate-limit destructive operations
- Network redundancy
从业务容灾视角而言:Twine spreads tasks of the same job across DCs and MSBs.
Evaluation
此章节乏善可陈,大致是:
- TaskControl works well for sharding manager.
- Offer 16 TaskControllers to support thousands of services.
- Autoscaling frees up to 25% of the web tier’s machines during off-peak hours.
- Host profiles improve performance and the overhead of switching host profiles is small.
- Offer 17 host profiles.
- twshared’s average memory and CPU utilization are ≈40% and ≈30%.
- Capacity buffer consolidation improved 3%.
- Turbo Boost improved 2%.
- Autoscaling improved 2%.
事实上 30% 的资源利用率并非很出色,相比 Borg 等有很大的提升空间。但是值得一提的是 Host Profile 的切换还是很迅速的,绝大部分在 4min 以内,相比之下不少公司的装机运维流程的效率和成功率还有很大的提升空间。
Experience
Path to Shared Infrastructure
- Make Twine capable of supporting a large shared pool
- Publicize the growth and health of twshared
- Set a strong example for others to follow
- Make migration mandatory
Lessons Learned
- Entitlements: 杂糅一个集群和 Quota 的概念,导致用户申请了太多的小集群。
- Customizations:we permitted some customizations that appeared useful initially, but later became barriers for fleet-wide optimizations.
- Supporting Global Services: We are replacing global Twine deployments with a new Federation system built a top regional Twine deployments to provide stronger capacity guarantees and more holistic support for a global-service abstraction.
总体看法
Move Machine vs Move Job
Twine 本质上更像是一个具备一定编排和调度能力的 Cluster API,它倾向在不同的业务之间腾挪机器构建集群,是一种机器适配 Job 的管理思想;而 Borg/K8S 的理念是在固定的资源池上,根据约束条件将 Job/Task 调度到最佳的机器上。
从一般效率上说,移动 Job 的效率肯定大大高于移动机器;其次从整体生命周期来看,机器的生命周期是缓慢的,而 Job/Task 的生命周期变动频率要高许多。因此针对超大规模私有云场景,我更倾向构建固定和统一的资源池,通过调度和隔离的手段来实现 Job 和机器的最佳匹配。
Unified Scheduling System & Sharing Pool & Isolation
我认为 Twine 的统一资源池更多体现在运维层面,即资源统一的管理、运维,可以在各个集群中比较高效的流转。事实上,不同集群之间的资源是隔离的,隔离能力是欠缺的,在节点维度未实现多样的任务共享。正如其所坦诚:
- Our legacy large services were optimized for utilizing entire machines running in private pools.
- Our stacking technology needed to mature and improve support for performance isolation.
事实上,如果没有在集群维度和单机维度实现运行多样的任务,特别是在线和离线业务,其资源利用率很难再更上一个台阶。
其次在调度上未形成统一的调度能力,Allocator 和 Application-Level Scheduler 之间是相对割裂的,未 能从全局和统一调度视角去看待调度最佳方案。
最后在资源类型未明显的提到分级,也不支持 overcommit,这也将大大影响其成本。
Global wide federation
当谈论 Region 粒度的 Scalibility 的时候,Twine 抨击了一波 Federation 的实现,表示其不如 Twine 简单优雅。但是到了 Lessons Learned 章节,又坦言:
Global Twine deployments did not provide the right abstraction for managing global services. We are replacing global Twine deployments with a new Federation system built a top regional Twine deployments.