The tail at large scale 阅读笔记
本人曾支持业务优化大规模服务容量,长尾请求是优化的最大瓶颈之一。本文结合论文和经验做小结沉淀:
- 构建模型分析长尾请求对服务的影响、衡量消除长尾请求的收益。
- 针对 Paper 的观点,谈谈工程领域具体实现方案,以及方案适用条件和优缺点。
注:本文很多经验来自不同团队,本人整理用于个人学习。
模型分析
业务采用 SLI、Latency 黄金指标衡量服务稳定性,SLI 计算如下:
QPS_success = QPS_total - QPS_error
SLI = QPS_success / QPS_total
通常大部分错误请求为超时的长尾请求。
服务 SLI 成本模型
服务 SLI 和营收有密切关系,SLI 过低通常对业务有损,表现为用户的体验下降甚至直接影响营收;其次大量 SLI 告警影响研发同学效率。
增加硬件资源通常可以提升服务的 SLI,一个典型微服务的 SLI 和服务 CPU 利用率关系如下,在资源固定的情况,随着服务请求上涨,CPU 利用率近乎线性上升,服务 SLI 缓慢下降,直到某个临界点服务 SLI 急剧降低:
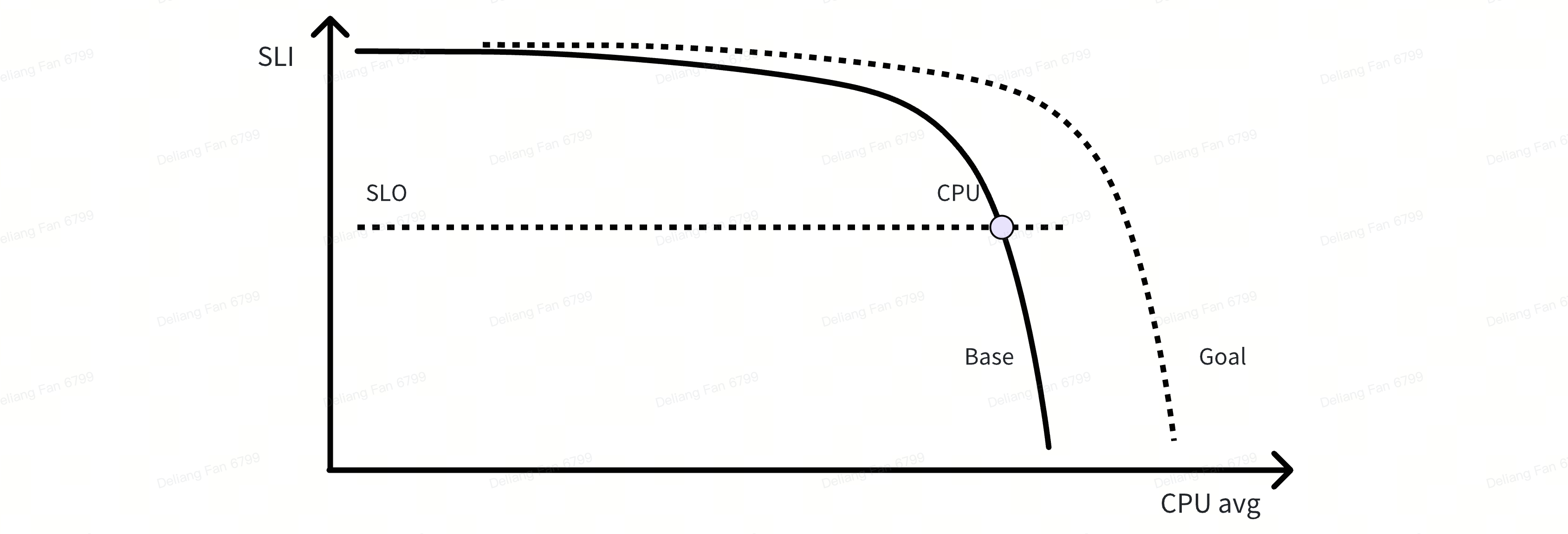
- SLI 99% 时,服务 CPU 平均利用率为 60%
- SLI 99.9% 时,服务 CPU 平均利用率为 50%
- SLI 99.99% 时,服务 CPU 平均利用率约为 20%
This content is only supported in a Feishu Docs 每提升服务 SLI 一个 9,需要付出越来越大资源成本,单业务收益呈现指数递减,因此服务 SLO 本质资源开销和业务收益的权衡。我们优化的目标是在给定资源下,通过多种手段降低因长尾导致的错误请求,提升 SLI,为业务优化容量奠定基础;进而在满足 SLO 的条件下,通过缩容降低资源成本,最终提升资源效率。
服务 SLI 稳定性模型
如 Paper 所言,造成长尾请求的因素多种,单机维度因素占主要部分。针对某个服务,假定每个节点请求的成功率为 p,它需要依赖会汇聚来自 n 个节点的请求,简化版的服务层面请求的成功率(SLI)为:
SLI = f(p),其中f(p) = p^n
引起长尾因素
造成长尾请求的因素有多种,本人所见和 Paper 大体相似,如下为一些典型场景: 节点层面
- 机器故障:机器故障导致问题,在百万节点的系统中,每天故障机器的数量非常可观。
- 硬件差异:不同的机型在磁盘、CPU、网卡的能力不同,差机型更容易成为瓶颈。
- 资源共享:超售和混部导致资源竞争,比如 CPU 受限、磁盘和网卡打满,影响服务稳定性。
- 流量差异:服务框架层(mesh)流量不均,造成部分实例热点问题。
非节点层面
- 网络拓扑问题,如交换机网卡故障或者网络打满。
- 业务自身问题。
方案
it advantageous to develop tail-tolerant techniques that mask or work around temporary latency pathologies, instead of trying to eliminate them altogether.
非常认同 Paper 如上观点,长尾问题持续困扰研发同学,并且多个团队持续投入了大量精力优化。手段可以分为两类:1. 持续提升节点请求的成功率 p;2. 优化稳定性模型,给定 p 下提升服务的 SLI。
提升请求成功率 p
事前消除潜在风险
解决或者缓解导致长尾的因素是最直接的手段,其思路在于找出根因和从根本上解决问题。影响节点请求成功率的因素原因多种多样而难以穷举,很难提前预测与防范,通常由问题驱动,分锅到家,往往耗费巨大的人力用于定位问题、分析原因、提供方案和 A/B 验证效果,如下是常见的问题,每一类问题都可以展开非常大的篇幅进行讨论。
- 单机稳定性:超售、混部等环境下,资源竞争和较低隔离能力造成大量的单机抖动问题。
- 流量均衡问题:因框架原因导致热点实例流量过高而引起的问题。
- 硬件能力:老旧机型算力差、HDD 磁盘、故障率高导致老旧机型成为木桶短板。
- 业务问题。
事后降低影响范围
单机因素导致实例异常时,异常通常会持续较长一段的时间。通过引入反馈机制,该机制快速鉴别异常实例,实施措施,降低异常实例影响时间,从而提升请求成功率 p。
该措施依赖如下约束:
- 指标系统:一套描述服务实例指标,一套实时、稳定的指标存储、索引系统。
- 异常规则:定义异常的指标规则。
- 实施措施:通过移除或者重建异常实例,降低异常实例的影响时间。
具体落地上,可实施的系统为:
- 服务框架:基于业务实例的 SLI、时延和持续时间等指标,采用限流和熔断措施降低异常实例的影响。
- 运营系统:基于机器和实例的基础指标,如 load (可引入业务指标),识别和下线异常机器,驱逐和异地重建异常实例。
反馈机制属于事后规避,其实时性和准确性受指标链路、异常规则的影响;而通用性是其优点。从实际经验来看,反馈机制是落地难度较低,效果良好。
优化容错模型
对冲请求
Paper 中对冲请求指的是针对每个请求,当该请求在一定时间(如 p99)未完成,那么再发送一个请求。从服务 SLI 稳定性模型来看,此时 SLI 和 p 的关系如下:
f(p) =(p + p(1-p))^n ;其中 p + p(1-p) > p
举例来看,假定 p 为 0.99,n 为 1,通过额外发送 1% 的请求,可以将成功率提升至 0.9999。
大规模的实施对冲请求存在很多客观约束,具体落地上,合适实施的系统为框架层或者 Mesh。
- 指标系统:一套描述服务实例的指标,一套实时、稳定性的指标存储、索引系统。
- 时延评估:服务时延是一个动态的指标,它随着请求量而上下波动,也随着业务需求和服务迭代而动态变化,二次
请求的阈值需要精准的评估标准。
- 标准化的服务框架:归类时延错误,封装和抽象重试触发条件和操作。
- 服务幂等的规范性:重试仅仅适用幂等操作,用户需要在幂等性上规范。
理论上对冲请求付出较低资源开销,即可良好地消除长尾问题。它的缺点是:1. 依赖标准的框架和规范的接口,同时要求精确的设定时延阈值;2. 提升链路追踪的复杂度;3. 极端情况或加剧雪崩。
Paper 还提到“Tied Requests”概念,即发送两个请求,当其中一个请求被处理时,该请求和会向另外一个请求发送一个取消的指令。该思路大大增加系统交互的复杂度,笔者其通用性表示质疑。
分级思想
Paper 简单的提及服务分级,并在一些系统中优先处理高级别的服务。从模型上来看,既然平均请求的成功率是一定的,可以通过牺牲低优服务的成功率,提升高优服务的成功率,从而优化服务的整体质量。
分级的思想在很多个层面会用到,比如在容灾上对业务进行分级,当出现大规模资源故障,或者流量突发时,通常保证有限的资源供给给高优的服务,对低优的服务进行降级,保障系统的整体运行。在在离线混部,我们会对资源进行分级,针对不同级别的资源提供不同的 QoS 能力,这些能力贯穿 CPU、内存、网络和磁盘 IO。
分级的难点在落实级别的定义,以及针对每个级别,多个系统需要提供的 QoS 具体的如何,各个系统的 QoS 是否具备良好的协同等等。
业务兜底
在一些 feed 流系统上,为了获取最佳的排序效果,一个请求可能会依赖非常多的下游做出最佳的排序,而不少下游服务是 nice to have 的,因此针对此类场景。业务侧可以提供多个层次的兜底措施,请求时延和请求结果上进行权衡。从模型来看,业务兜底本质降低了对 n 的依赖,从而在 p 一定的条件下提升服务整体的 SLI。
业务兜底的具体实现因场景而异,诸如兜底的级别、策略等等。常见于 feed 流系统,比如视频、广告、商品等业务场景的排序,而 feed 流通常是非常核心的系统,因此通常会引入多个层次的兜底手段,保证系统的高可靠性。