奔跑在 K8S 上的 Tensorflow (二) 冉冉升起的 kubeflow
本文主要介绍 kubeflow 项目,重点分析 tf-operator 和 kube-batch 的原理,以及在蘑菇街的落地经验。
Kubeflow 简介
The Kubeflow project is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable.
正如 kubeflow 官网 所言,kubeflow 旨在支持多种机器学习框架运行在 K8S 上,比如 tensorflow, pytorch, caffee 等常见框架。它通过提供对应的 operator,基于 K8S 的 Pod/Service 等基础资源为框架提供与之相配的更高层次的资源。比如 tf-operator 为 tensorflow 提供了 TFJob 资源,以满足 tensorflow 分布式训练的资源和拓扑需求,最终达到一键拉起分布式机器学习集群的效果。
Kubeflow 包含如下 operator,分别对应主流的框架。其中 tf-operator 的人气最高,近 600 个 star,较为成熟,已在蘑菇街的生产环境稳定运行一段时间;而其它 operator 的人气很低,成熟度值得商榷。

Tf-operator
使用 tf-operator 前,要求配置 K8S 和 Docker 以支持 GPU 资源,具体的步骤请找 Google。
Distributed tensorflow
首先介绍 tensorflow 的分布式训练,tensorflow 支持如下三种分布式策略:
- MirroredStrategy:适用于单机多卡的训练场景,功能有限,不在本文讨论范围内。
- ParameterServerStrategy:用于多机多卡场景,主要分为 worker 节点和 PS 节点,其中模型参数全部存储在 PS 节点,worker 在每个 step 计算完梯度后向 PS 更新梯度,蘑菇街当前使用这种方案。
- CollectiveAllReduceStrategy:用于多机多卡场景,通过 all-reduce 的方式融合梯度,只需要 worker 节点,不需要 PS(parameter server) 节点,从另外一个角度说,该节点既充当 worker 角色,又充当 PS 角色。该方案是带宽优化的,具有性能好,可扩展性强的特点,是 tensorflow 未来推荐的方案。
以 ParameterServerStrategy 为例,一个分布式训练集群至少需要两种类型的节点:PS 和 worker。由于在训练中需要 worker 一个节点来评估效果和保存 checkpoint,因此单独把该节点作为 chief(或者叫 master) 节点。通常情况下,一个集群需要多个 worker 节点,多个 PS 节点,一个 chief 节点。所有 worker 节点的 CPU/内存/GPU等资源配置完全相同,所有 PS 节点的 CPU/内存等资源配置也相同。从资源拓扑角度出发,如果能够提供一种 K8S 资源,用户可以基于该资源定义 PS/worker/chief 的数量和规格,用户就可以一键式创建分布式集群,大大简化了分布式集群的部署和配置。tf-operator 定义了 TFJob 资源,用户可以借助 tf-operator 在 K8S 上一键拉起分布式训练集群。
从 tensorflow 分布式训练的使用方式出发,用户在启动每个节点的任务时,需要传入集群所有节点的网络信息。这意味着分布式训练集群的每个节点需要预先知道所有其它节点的网络地址信息,即要求服务发现功能。tf-operator 基于 K8S headless service,完美的提供了服务发现功能。
Tf-operator 详解
Tf-operator 代码不多,相对容易理解,特别对熟悉 kube-controller-manager 同学而已,非常容易上手。
部署 tf-operator 后,我们需要在 K8S 创建对应的 TFJob CRD。之后就可以创建 TFJob 资源,如下样例定义了一个具有 10 个 worker,4 个 ps,1 个 chief 的分布式训练集群。从 TFJob 参数不难发现,它对ParameterServerStrategy 和 CollectiveAllReduceStrategy 这两种策略方式都支持,只是在 CollectiveAllReduceStrategy 场景下,无需要设置 PS 资源。
apiVersion: "kubeflow.org/v1alpha1"
kind: "TFJob"
metadata:
name: "example-job"
spec:
replicaSpecs:
- replicas: 1
tfReplicaType: CHIEF
template:
spec:
containers:
- image: gcr.io/tf-on-k8s-dogfood/chief_sample:latest
name: tensorflow
restartPolicy: OnFailure
- replicas: 10
tfReplicaType: WORKER
template:
spec:
containers:
- image: gcr.io/tf-on-k8s-dogfood/worker_sample:latest
name: tensorflow
restartPolicy: OnFailure
- replicas: 4
tfReplicaType: PS
template:
spec:
containers:
- image: gcr.io/tf-on-k8s-dogfood/ps_sample:latest
name: tensorflow
Tf-operator 启动后,通过 list-watch 不断的监听 TFJob 资源相关事件,当收到创建 TFJob 事件时,tf-operator 依次创建 PS/Worker/Chief(Master) Replica 资源。以 PS Replica 为例,根据 replicas 数量依次创建等同数量的 pod,并为每个 pod 创建 headless service。此外,它还生成 TF_CONFIG 环境变量,这个环境变量记录了所有 pod 的域名和端口,最终在创建 pod 时候注入到容器中。

Kube-batch
虽然 Kube-batch 不属于 kubeflow 项目,但是却和分布式训练息息相关。分布式训练要求集群保持一个整体,要么所有的 pod 都能成功创建,要么没有一个 pod 能被创建,即调度应该支持 pod 群维度的调度。试想资源处于临界状态时,如果采用默认的调度器调度一个分布式训练集群,则会导致部分节点因资源不足而无法成功调度,那些成功创建的 pod 空占用资源,但是无法进行训练。
顾名思义,batch 者,批量也。正如其官网所说:kube-batch 是一个运行在 K8S 上面向机器学习/大数据/HPC 的批调度器。它抽象 PodGroup 资源,提供了群调度的功能。Kube-batch 的基本流程如下图,它 ListWatch Pod, PodGroup 和 Node 等资源,然后依次经过 claim, allocate, preempt 等步骤,最终完成调度。
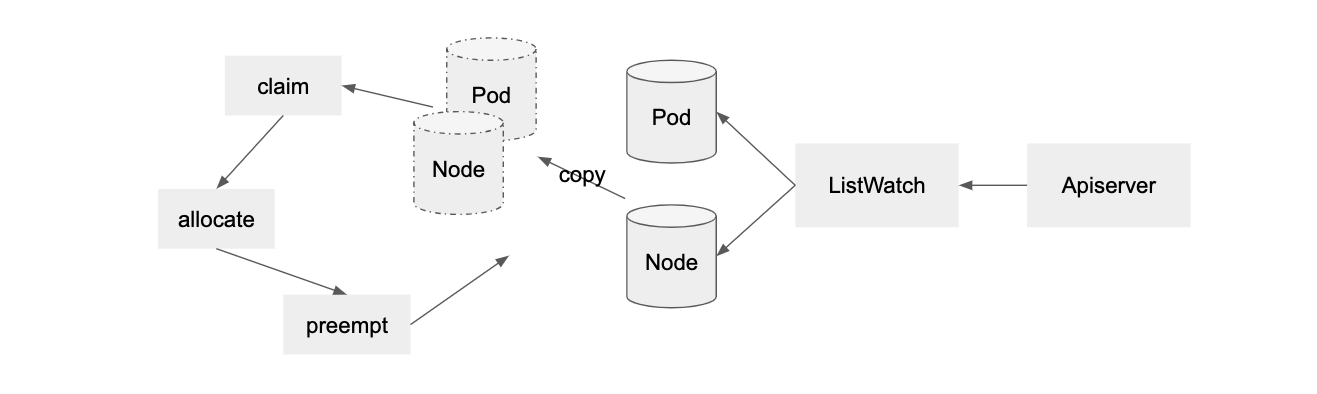
目前 kube-batch 功能薄弱,成熟度有待商榷。比如 kube-batch 只有 predict 功能,没有 priority 功能。并且 predict 功能也非常薄弱,仅支持部分基础的 filter,比如 PodMatchNodeSelector, PodFitsHostPorts 以及基本的资源调度等。特别是 PodAffinity 特性,对于 PS-Worker 架构非常有用,因为 PS 节点的网络流量非常大,所以需要 PS 节点之间反亲和,将各个 PS 节点分散。此外,kube-batch 也不支持多任务之间依赖关系。
最后
从落地情况来看,tf-operator 的功能满足基本要求,稳定性较高。但是在故障恢复稍有欠缺,对于 pod 级别的故障,依赖 kubelet 来恢复;对于 node 级别的故障,目前还不支持故障恢复。分布训练下,故障概率随着 worker 数量和训练时间的增加而增加。worker 作为无状态节点,故障恢复既是可行的,也是非常有必要的。
Kube-batch 的落地效果差强人意,社区的维护力度较低。除了功能薄弱以外,我们也碰上了诸多的问题,处于勉强可用状态。个人建议可用将 pod 群维度的资源判断功能放到上层,只有当空闲资源满足创建整个分布式训练集群时,再将请求发送给 K8S,由 K8S 默认的调度器完成调度,当然,这种方式也存在一些缺点。