GPU 兼容性的那些事
在把 GPU 资源纳入 K8S 管理的过程中,面临存在多个 Nvidia GPU 型号的问题,其中较老版本的有 Kepler 系列,也有较新的 Pascal 和 Volta 系列。这些不同版本的硬件对驱动和 Cuda 框架版本有不同兼容性的要求,而驱动和 Cuda 对 K8S 乃至上层的机器学习框架 Tensorflow 等等也有兼容性的要求。
如果能够统一驱动、Cuda 等模块的版本,将大大降低维护成本。本文重点分析将 GPU 纳入 K8S 管理过程中各个模块对兼容性要求,并给出蘑菇街的实践经验。
Docker 支持 GPU 原理
关于 Docker 支持 GPU 的原理,详情请见 Enabling GPUs in the Container Runtime Ecosystem,简而言之,通过在 runc 模块加入 nivida-container-runtime-hook,支持将宿主机的显卡和驱动映射到容器中。

从上图可以看出,如果 K8S 要支持管理 GPU 资源,需要增加如下模块或者配置:
- 宿主机硬件驱动:需要安装 Nvidia Driver
- 宿主机 docker:需要将更新 docker 配置参数,并安装 nvidia-container 相关库,详情请见 nvidia-docker
- 宿主机 K8S:需要增加 k8s-device-plugin,用于统计 GPU 资源。
- 容器中 Cuda 相关库:需要安装 cuda toolkit,包括 cuda,cudnn。
- 容器中机器学习框架,如 Tensorflow,Pytorch 等等。
兼容性要求
1. 硬件和 Nvidia Driver 之间的兼容要求
Nvidia 官网关于 GPU 硬件和驱动的兼容性要求如下,从个人了解的情况来看,Kepler 和 Fermi 因过于古老,即将被淘汰;而 Turing,Volta 虽然算力强大,但是价格昂贵;Maxwell 和 Pascal 系列显卡应该是保有量较高的显卡。
| Hardware Generation | Compute Capability | Driver 384.111+ | Driver 410.48+ | Driver 418.39+ |
|---|---|---|---|---|
| Turing | 7.5 | No | Yes | Yes |
| Volta | 7.x | Yes | Yes | Yes |
| Pascal | 6.x | Yes | Yes | Yes |
| Maxwell | 5.x | Yes | Yes | Yes |
| Kepler | 3.x | Yes | Yes | Yes |
| Fermi | 2.x | No | No | No |
2. CUDA 和 Nvidia Driver 之间的兼容要求
Nvidia 官网关于 CUDA 和驱动版本的兼容性要求如下,目前 CUDA 9.0 还是比较成熟和通用的版本,但是有些深度学习框架会要求运行在 CUDA 10 上,所以建议根据实际业务情况选择 CUDA 9.0 和 CUDA 10.0。
| CUDA Toolkit | Linux x86_64 Driver Version |
|---|---|
| CUDA 10.1 (10.1.105) | >= 418.39 |
| CUDA 10.0 (10.0.130) | >= 410.48 |
| CUDA 9.2 (9.2.88) | >= 396.26 |
| CUDA 9.1 (9.1.85) | >= 390.46 |
| CUDA 9.0 (9.0.76) | >= 384.81 |
| CUDA 8.0 (8.0.61 GA2) | >= 375.26 |
| CUDA 8.0 (8.0.44) | >= 367.48 |
3. CuDNN 的兼容要求
CuDNN 是 NVIDIA 打造的针对深度神经网络的加速库,虽然不是必需品,但是建议安装以提升速度。CuDNN 对 CUDA 和驱动均有兼容性要求,详情请见官网 CuDNN support matrix。
总体而言,CuDNN 的兼容性比较友好,能够支持较大范围的 CUDA 和驱动版本,如果考虑到稳定性,建议选择 7.6.0 版本的 CuDNN。
4 CUDA 对系统的兼容性要求
Cuda 9.0 对系统的兼容性要求如下:
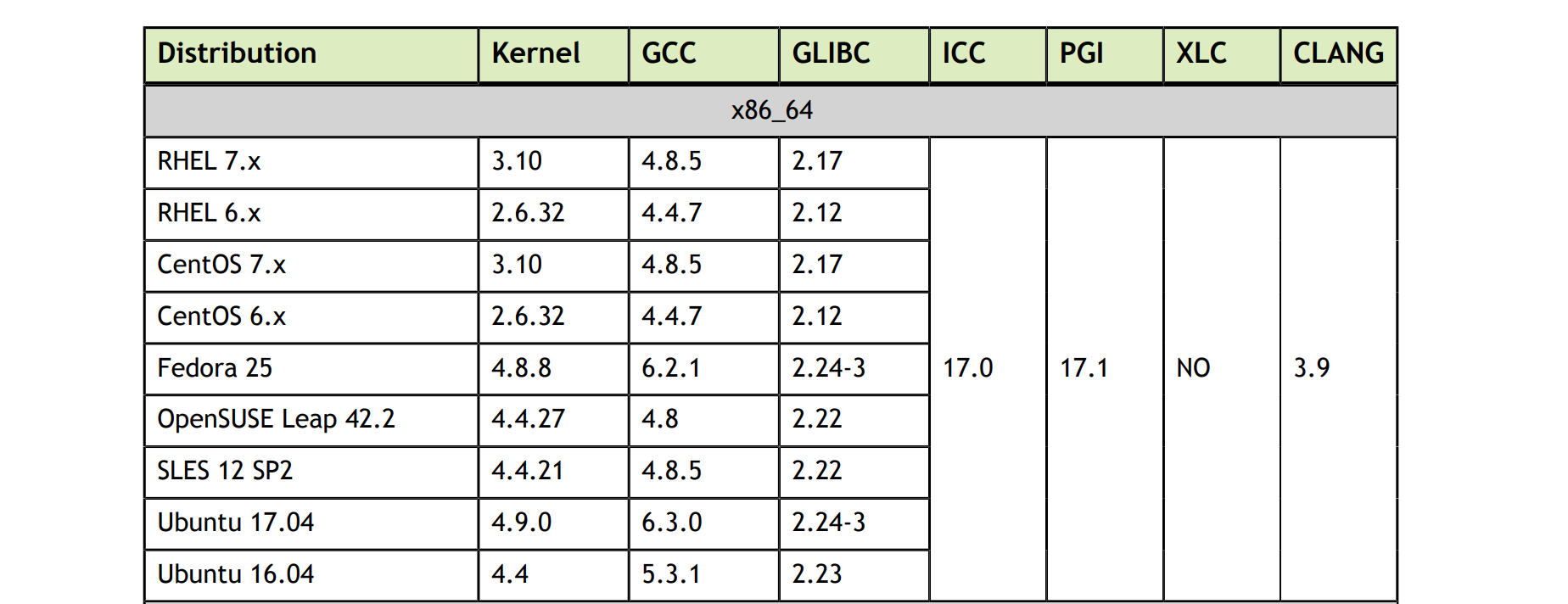
Cuda 10.0 对系统的兼容性要求如下:
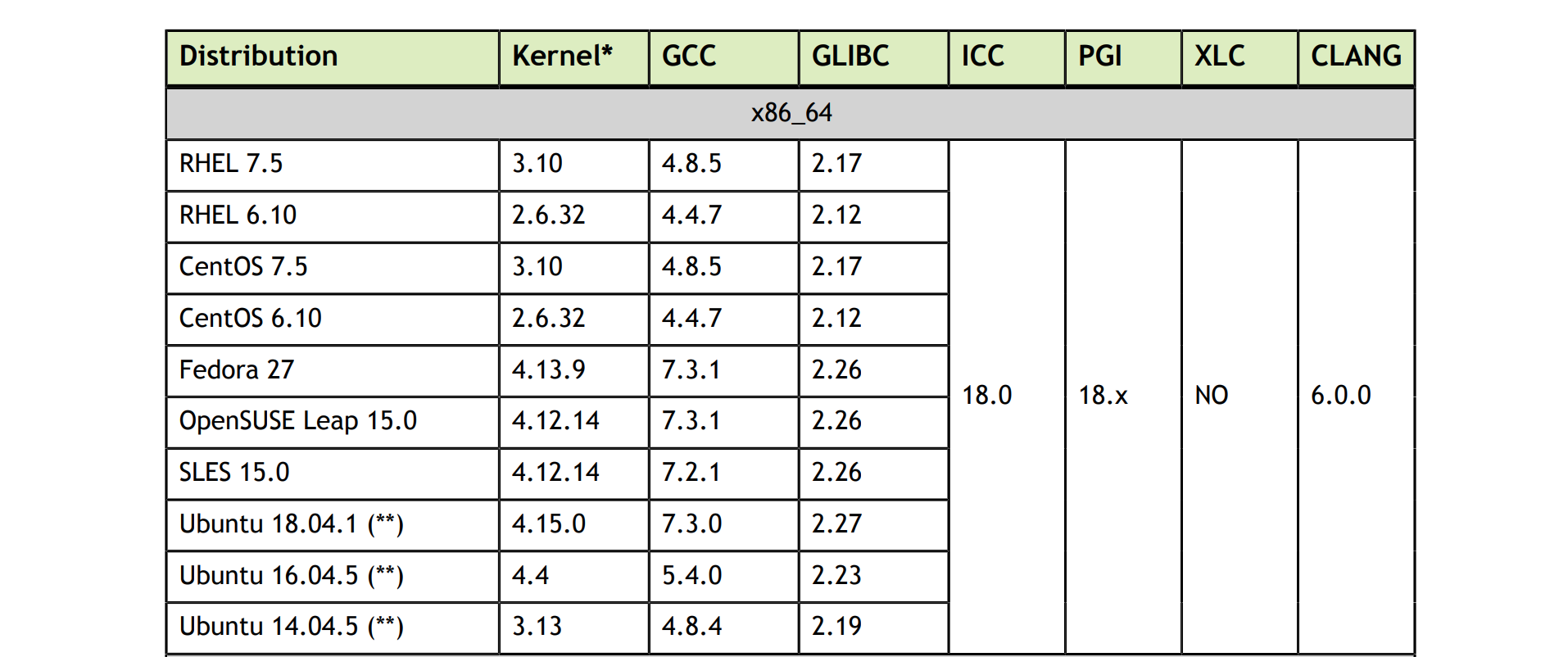
从个人经验来看,目前 CentOS7 是主流的操作系统版本,3.x 的内核已很稳定成熟,如果没有历史包袱,建议采用 CentOS 7.5 版本,能够兼容 CUDA 9.0 和 CUDA 10.0。
5. K8S & k8s-device-plugin
K8S 从 1.10 起对 GPU 已有较为成熟的支持,GPU 资源管理和调度的功能比较稳定。它采用插件的方式,通过在每个 GPU 节点运行 k8s-device-plugin Daemonset 来管理和统计 GPU 资源,k8s-device-plugin 对兼容性要求如下:
- Nvidia Driver >= 361.93
- K8S >= 1.10
6. 深度学习框架的兼容性要求
Tensorflow 和 Pytorch 是当前主流的机器学习框架,它们对 GPU 硬件,CUDA 有兼容性要求。
虽然 Tensorflow 于 2018 年底发布了 2.0,但是由于 API 变化过大,似乎到目前为止未得到广泛的使用。个人认为主流的 Tensorflow 版本还是在 1.8 - 1.14 之间。Tensorflow 对兼容性的要求如下:
- GPU 硬件:要求 Compute Capability >= 3.5,即 K40 及以上系列硬件,包括 Kepler 部分系列(K40, K80),所有 Maxwell,Pascal,Volta 和 Turing 系列硬件。
- CUDA 版本:Tensorflow 从 1.13 起要求 CUDA 10,更早版本的 Tensorflow 支持 CUDA 9.0。
- CuDNN 版本:>= 7.4.1。
Pytorch 的兼容性较 Tensorflow 好些,从 1.0 - 1.2 版本均支持 CUDA 9 和 CUDA 10。
经验和结论
截止至 2019 年 5 月,从业务的角度来看,Tensorflow(1.8-1.12) 和 Pytorch(1.0-1.2) 是主流的深度学习框架;从资源的角度来看,Maxwell,Pascal,Volta 系列的 GPU 是当今主流的显卡。Kubernetes 作为 GPU 的资源管理平台,在统一管理各种型号硬件的同时,更需要支撑好业务,即支撑主流的深度学习框架。同时我们还需要在保证各个模块兼容性的前提下,尽量避免维护多个版本,因而各个模块版本的选取非常重要。从理论和实际经验出发,推荐前瞻型和保守型的两套方案。
前瞻型
各个版本相对较新,功能丰富,兼容性更好,稳定性稍差。
- Nvidia Driver: 410.48
- CUDA: 10.0
- CuDNN: 7.6.0
- K8S: >= 1.10
- Tensorflow: 1.8 - 1.14
- Pytorch: 1.0 - 1.2
- OS: CentOS7.5, Ubuntu 16.04
保守型
各个版本相对较旧,稳定性较好,兼容性更差。
- Nvidia Driver: 384.111
- CUDA: 9.0
- CuDNN: 7.6.0
- K8S: >= 1.10
- Tensorflow: 1.8 - 1.12
- Pytorch: 1.0 - 1.2
- OS: CentOS7.5, Ubuntu 16.04