云上成本优化和架构演进
本文谈谈近期所做的一些事情,通过深入利用云上的服务和优化现有的离在线架构,大大降低大数据、机器学习和在线业务的成本,同时提升弹性。云厂商几年前通常以 K8S 集群的形态推出容器服务,每个集群拥有各自的 Master 和 Worker 节点,运行在云主机上,和客户自己搭建的 K8S 并没有太大的差别。随着近些年快速迭代,云上 K8S 的网络和存储能力得到大大的增强,容器产品日益丰富,弹性能力愈发强大,为离线和在线业务带来更多的可能性。例如,结合裸金属和容器云实例可给在线业务带来极致的成本和日间弹性的收益。Serverless K8S 非常适合深度学习(TFJob)、Spark 等离线业务,既能充分利用海量的弹性资源,避免任务等待,又能优化资源配置。
按需选择资源类型
细数各个云厂商的容器产品,几乎清一色的可分为三类 K8S 集群、Serverless K8S 和容器云实例(类似 OpenStack Zun,又称 Serverless Container),最大的区别是产品名称的英文缩写。
如今的 K8S 集群不仅仅支持云主机,还同时支持裸金属资源,甚至可通过 Virtual Kubelet 对接容器云实例。这些资源的差异点主要体现在成本和弹性,用户可以根据业务情况在弹性和成本之间做出更好的选择。从磁盘性能角度出发,云硬盘的读写延时在 1ms 左右,IOPS 在万级别;通常采用 NVME SSD 裸金属的读写延时约为 50us,IOPS 至少在十万级别,所以对磁盘 IO 要求很高的业务,应该选择裸金属。
| 资源类型 | 成本 | 弹性 |
|---|---|---|
| 裸金属(物理机) | 成本低,核时成本约为云主机的 70% | 交付时间最长,甚至缺货 |
| 云主机(虚拟机) | 成本中,核时成本约为容器云实例的 70% | 至少几分钟 |
| 容器云实例或者 Serverless K8S | 成本高,适合波峰波谷显著的业务 | 秒级弹性 |
综上不难发现,如果将云主机替换成裸金属,将能大大的节省开支。事实上,我们正是通过把大部分 K8S 云主机替换成裸金属,既大大的降低成本,还获得更好的磁盘性能,对于临时的资源需求则通过扩容云主机或者容器云实例来满足。
在线业务的日间弹性
弹性是电商相关技术领域一个长久的话题,笔者前博文 聊聊云上弹性的演进 已做了详细的介绍,从大促的弹性再到日间的弹性,它的背后是成本,是效率。由于大促的频率一般较少,一年也就数次,具有充足的时间扩容资源和部署业务,公有云上大促场景的弹性扩容不再是个难题。但是日间场景的扩缩容频次高,对资源实时性和服务治理能力的要求更严格。由于现有技术体系具备良好的服务治理(非 K8S Service)能力,所以当公有云推出具备秒级弹性的容器云实例后,意味着客观上已具备把弹性演进到日间的基础。
下图基本代表了电商行业的日间流量分布,20 点到 24 点是一天的流量高峰,峰值几乎为是其它时间点峰值的数倍,所以如果采用一个固定的裸金属资源池应对日常流量,利用容器云实例应对晚间 4 个小时的峰值流量,将能大大的优化成本。
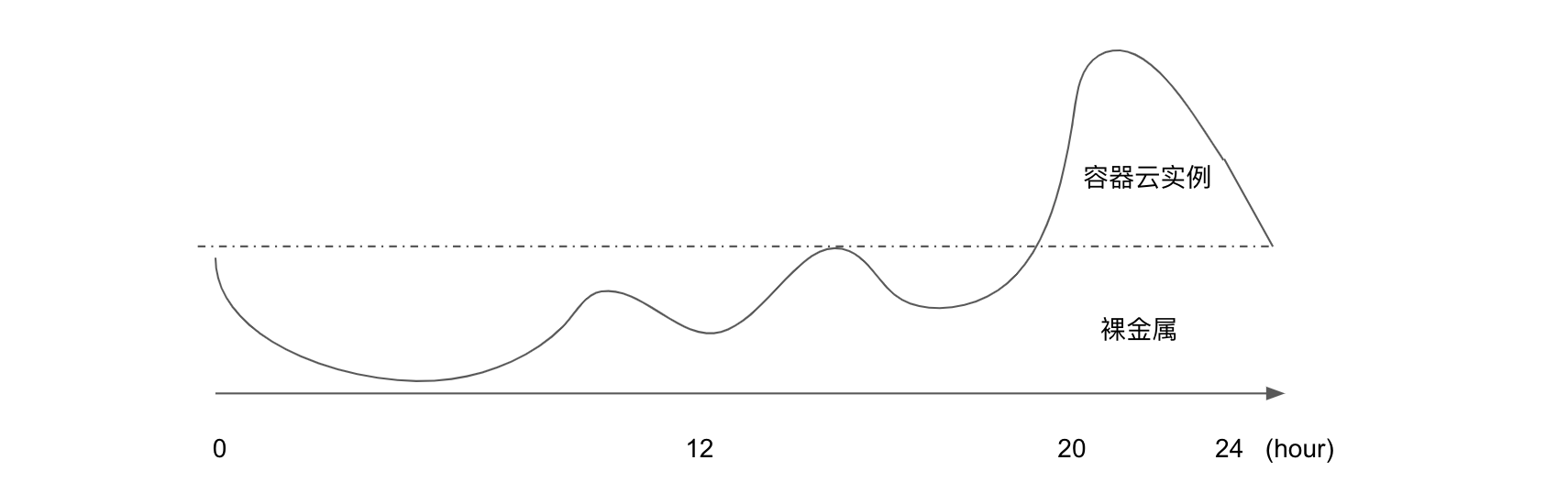
从 19 年开始,各个云厂商逐步推出相关方案,几乎采用 VK 衔接 K8S 和容器云实例,容器云实例服务在 K8S 中以一个 virtual node 的形式存在,通过 nodeselector 或者 node affinity 指定 virtual node 扩容资源,从而实现日间秒级的弹性。通过逐步将峰值流量切割到容器云实例,获得较好的成本优化收益和弹性能力。
+--------------+
| K8S Master |
+--------------+
+---------------+ +--------------+ +------------------+
| Physical Node | | EC2 | | Virtual Kubelet |
+---------------+ +--------------+ +------------------+
|
V
+-------------------+
| 容器云实例 |
+-------------------+
如官方所言,Virtual Kubelet(以下简称 VK) 目标是赋予 K8S 容器云实例的能力,实际上使用 VK 会损失 service 特性,如果业务依赖 K8S service,应当避免使用 VK。
The primary scenario for VK is enabling the extension of Kubernetes API into serverless container platforms like ACI and Fargate, though we are open to others. However, it should be noted that VK is explicitly not intended to be an alternative to Kubernetes federation.
离线 业务 On Serverless K8S
当 Hadoop 于 2006 年诞生时,那时服务器网卡 0.1 Gbps 为主,在海量数据下移动计算比移动数据更高效,所以大数据的体系下计算和存储是融合的。相比 CPU,随着网络性能一枝独秀的高速发展,当前 10Gbps 网卡已是最低配置,有些高配的服务器网卡速度甚至高达 100Gbps,如今数据的移动速度是如此快速,移动成本如此低廉,再加上分离后的架构更有优势,所以计算和存储分离是大势所趋,也是当今各大云厂商主推的大数据方案。
Remote Shuffle Service 和 Dynamic Allocation Support 是 Spark 3.0 版本的两个亮点,前者意味着 Spark 支持在远端 shuffle 数据,后者支持 Spark On K8S 动态分配资源;同样在 2019 年发布的 Flink 1.10 也进一步增强对容器的支持,如动态资源分配等功能,种种迹象表明,K8S 正取代 YARN 成为大数据的资源管理和调度系统。数据和计算的分离为计算模块弹性提供基础,除了已容器化的 TFJob,我们正把 Spark 和 Flink 迁移到 K8S,赋予离线计算模块更大的弹性。
下图是 Spark 和 TFJob 资源池每日 CPU 和内存的分配情况,不难看出二者均存在分明显的波峰和波谷,在波峰时段,CPU 资源存在激烈的资源竞争,影响部分任务的产出时间,在波谷阶段存在大量的的资源空闲。但是整体而言,CPU 的平均分配率在 50% 以下,内存的平均分配率更低。从 CPU 和内存的资源配比角度来看,这些任务平均的分配比为 1:2.5,而宿主机的 CPU 和内存配比约为 1:3.5,存在明显的内存资源浪费。


通过将 TFJob、Spark 和 Flink 等离线任务容器化并迁移到 Serverless K8S,大大的优化资源和提升弹性。云厂商为 Serverless K8S 维护充裕的资源大池,避免任务竞争和等待,在相同的成本下更快地产出结果。其次 Serverless 精确到秒的按需收费,避免资源闲置时的成本,虽然 Serverless K8S 单位核时更贵,但是整体而言成本要更低。最后由于 CPU 和内存的配比可以按需分配,消除内存资源闲置时的成本。
未来的展望——离在线混部
离在线混部提升资源利用率的一个热点话题,但是需要攻克不少的技术难点,包括集群的调度系统,Linux 的调度系统,任务优先级和抢占,IO 的隔离等等,最核心要保证在线业务的 RTT 不受到离线业务的影响。K8S 的优先级调度策略、Pod 的 QoS 策略为离在线混部提供一定的能力,但是还远远不够。Linux 的默认的 CFS 调度策略不能区分离在线业务,无法支持在线业务抢占离线业务,其次基于 Cgroup 的磁盘 IO 的限速缺陷又是一个难点,除非有资深专业的团队优化定制内核,否则离在线业务混部依旧有一段路要走。