KubeZoo 的核心理念 —— 协议转换(二)
注:KubeZoo 是本人参与的项目,此文主要由本人撰写,遂同步到个人博客。
本文是 KubeZoo 系列技术文章的第二篇,将重点介绍 KubeZoo 的核心理念和关键实现 —— 协议转换。
KubeZoo 的项目地址请见:https://github.com/kubewharf/kubezoo
理念简介
从租户的视角来看,无论是 namespace scope 还是 cluster scope 的资源,用户都有完整和独立的视角,比如租户 A 拥有名字为 foo 的 namespace,租户 B 也可以拥有名字为 foo 的 namespace,而且这两个 namespace 只是名字一样,其资源和权限实际上是互相隔离的。但是从 Kubernetes 的视角来看,其对 namespace 的资源要求在 namespace 内是命名唯一的,对于 cluster scope 的资源,其要求在全局上是命名唯一的。
当所有的租户都共享同一个 Kubernetes 时,为了解决多个租户具备完整独立视角和 Kubernetes 要求在 namespace/scope cluster 不同层次命名的唯一性的矛盾,我们提出了协议转换的理念,从而解决命名唯一性的问题。
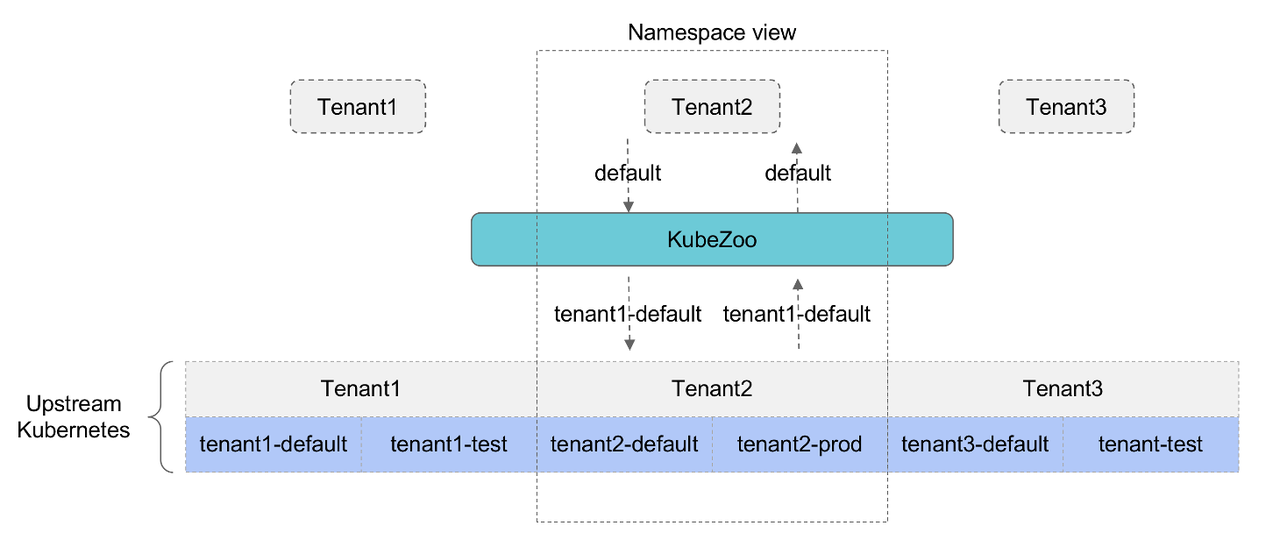
如上图所示,由于每个租户的名字/Id 是全局唯一的,因此如果在相关的资源名字上增加租户的标志,也就间接保证了在实际的 Kubernetes 控制面上保证了资源全局的唯一性;从租户的视角来看,如果我们对租户呈现其资源时,将相关的前缀剥离,即保证了租户的真实呈现视角和隔离性。以 namespace 视角为例,比如租户 tenant2 有 default 和 prod 两个 namespace,其在上游的真实 namespace 则是加上了租户的前缀,故为 tenant2-default 和 tenant2-prod。因此 KubeZoo 在租户和上游的 Kubernetes 集群充当了中间的转换适配层,接受租户的请求和上游 Kubernetes 的返回,并根据不同类型的资源进行不同的处理。
核心实现
KubeZoo 基于“协议转换”核心理念实现控制面多租户功能,通过在资源的 name/namespace 等字段上增加租户的唯一标志,从而解决不同租户的同名资源在同一个上游物理的 K8s 冲突问题,该思想和 Linux 内存管理有如出一辙之处。
K8s 原生 API 大致可以被划分为如下 4 类:
- Namespace scope:如 pod, pvc, statefulset, deployment etc;
- Cluster scope:如 pv, namespace etc;
- Custom:用户定义的资源;
- Non-resource:如 openapi / healthz / livez / readyz 以及日志监控等 etc。
通过对上述 API 采取对应的协议转换方案,最终为绝大部分的 API 提供多租户能力,经分析检验, KubeZoo 的一致性测试通过率高达 86%。
Namespace Scope 资源
K8s 大概有 40 多种 namespace scope 的资源,比如 deployment / statefulset / pod / configmap 等。通过在每个资源的 namespace 字段关联租户信息,从而实现 namespace scope 资源的多租户能力。
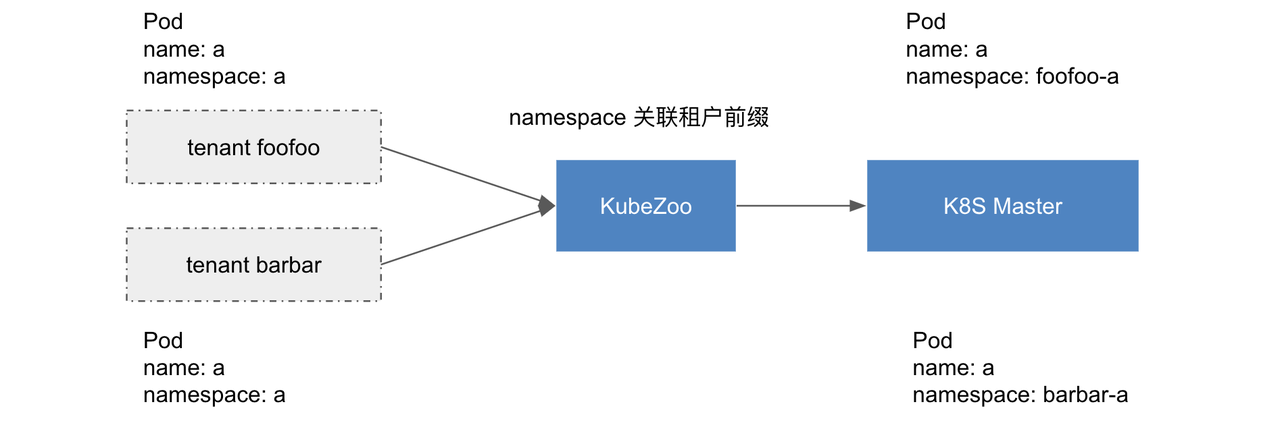
对于租户不同类型的请求,KubeZoo 首先从请求的证书中解析租户信息,之后具体转换如下:
- POST:在 request body 的 namespace 和 request url 的 namespace(如果有的话) 字段添加租户前缀,然后将请求转发至上游 K8s 完成资源创建;对于 response body,删除 namespace 中的租户前缀,最后把请求返回给租户。
- GET
- 查询/监听 某个资源:在 request url 的 namespace 字段增加租户前缀,然后将请求转发至上游 K8s 完成资源查询;对于 response body,去除 namespace 中的租户前缀,最后把请求返回给租户;
- 罗列/监听 ns 的资源:在 request url 的 namespace 字段增加租户前缀,调整 label selector 中涉及 namespace 相关的值,然后将请求转发至上游 K8s 完成资源查询;对于 response body,去除 namespace 中的租户前缀,最后把请求返回给租户;
- 罗列/监听 租户的资源:查询上游 K8s所有此类资源,KubeZoo 根据 namespace 的租户前缀匹配本租户的所有此类资源;同时去除 namespace 中的租户前缀,最后把请求返回给租户。
- PUT:在 request body 的 namespace 和 request url 的 namespace(如果有的话) 字段添加租户前缀,然后将请求转发至上游 K8s 完成资源更新;对于 response body,去除 namespace 中的租户前缀,最后将请求返回给租户。
- DELETE
- 删除某个资源:在 request url 的 namespace 字段增加租户前缀,然后将请求转发至上游 K8S 完成资源删除;对于 response body,去除 namespace 中的租户前缀,最后将请求返回给租户;
- 删除某些资源:在 request url 的 namespace 字段增加租户前缀,调整 label selector 涉及 namespace 相关的值,然后罗列符合要求的资源,对于属于本租户的资源,逐个删除;对于 response body,去除 namespace 中的租户前缀,最后把请求返回给租户。
对于 POST / GET / PUT 操作的协议转换过程,所依赖的 ownerReference 资源名字也需要做相关处理,对于 Cluster Scope 的资源名字,其处理逻辑请见下节“Cluster Scope Resource”;对于 Custom Resouce 的资源名字,其处理逻辑等请见下文“Custom Resource”。ownerReference 的命名转换是普遍适用的场景,不仅适用于本节 namespace scope resource,还包括 cluster scope resource 和 custom resource 等,后文不再累述。
Cluster Scope 资源
K8s 大概有 20 多种 cluster scope 的资源,比如 pv / namespace / storageclass 等等。通过在 name 关联租户信息,从而实现 cluster scope 资源的多租户能力。
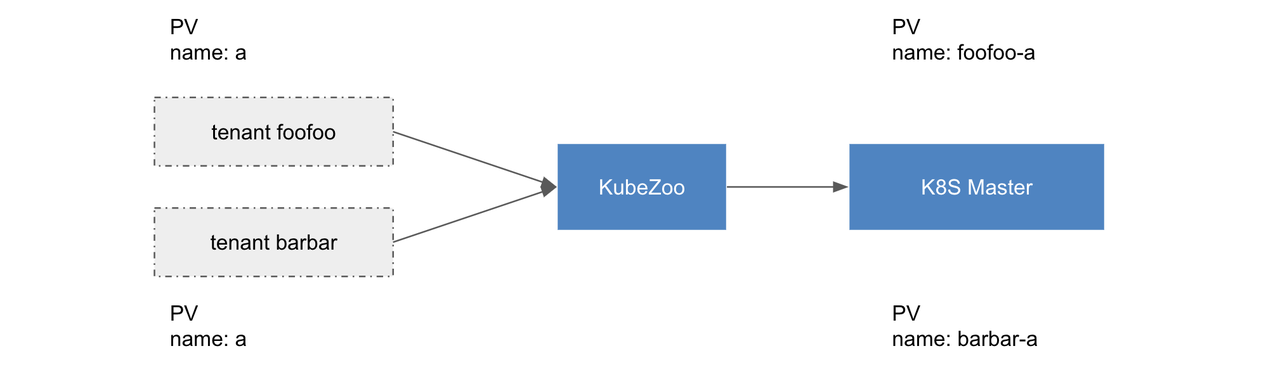
对于租户不同类型的请求,KubeZoo 首先从请求的证书中解析租户信息,之后具体转换如下:
- POST:在 request body 的 name 字段添加租户前缀,然后将请求转发至上游 K8S 完成资源创建;对于 response body,去除 name 中的租户前缀,最后把请求返回给租户。
- GET
- 查询/监听 某个资源:在 request url 的 name 字段增加租户前缀,然后将请求转发至上游 K8s 完成资源查询;对于 response body,去除 name 中的租户前缀,最后把请求返回给租户;
- 罗列/监听 租户的资源:查询上游 K8s 所有此类资源,KubeZoo 根据 name 匹配的租户前缀匹配本租户的所有此类资源;同时去除 name 中的租户前缀,最后把请求返回给租户。
- PUT:在 request body 的 name 和 request url 的 name(如果有的话)字段添加租户前缀,然后将请求转发至上游 K8s 完成资源更新;对于 response body,去除 name 中的租户前缀,最后将请求返回给租户。
- DELETE
- 删除某个资源:在 request url 的 name 字段增加租户前缀,然后将请求转发至上游 K8s 完成资源删除;对于 response body,去除 name 中的租户前缀,最后将请求返回给租户;
- 删除某些资源:罗列符合要求的资源,对于属于本租户的资源,逐个删除;对于 response body,去除 name 中的租户前缀,最后把请求返回给租户。
对于 node 类型的资源,由于 KubeZoo 方案是倾向由弹性容器提供数据面多租户的能力,因此上游集群不会纳管实际的计算节点,故实现上采取屏蔽 node 类型的资源的做法。
Custom 资源
Custom Resource Definition(CRD)是一种特殊的 cluster scope 资源,由于其 name 由 group + plural 组成,我们选择在 group 前缀关联租户信息,除此处细节差异外,其它的逻辑则和上述 “cluster scope resource” 基本保持一致,详情如下图所示。
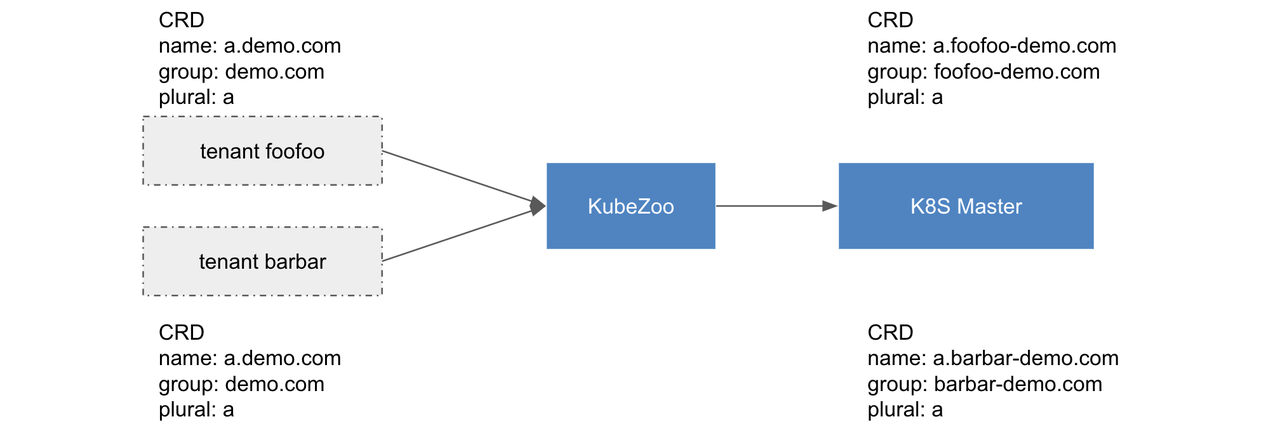
Custom Resource(CR)可以分为 namespace scope 和 cluster scope,我们以 namespace scope 的 CR 的请求为例,KubeZoo 从证书解析租户信息后,具体的转换逻辑如下:
- POST: 往 request url 的 group / namespace 和 request body 的 group / namespace 字段添加租户前缀,然后将请求转发至上游 K8s 完成资源创建;对于 response body,去除 group / namespace 中的租户前缀,最后将请求返回给租户。
- GET
- 查询/监听 某个资源:向 request url 的 group / namespace 字段增加租户前缀,然后将请求转发至上游 K8s 完成资源查询;对于 response body,去除 group / namespace 中的租户前缀,最后把请求返回给租户。
- 罗列/监听 ns 的资源:在 request url 的 group / namespace 字段增加租户前缀,调整 label selector 中和 namespace 相关的值,然后将请求转发至上游 K8S 完成资源查询;对于 response body,去除 namespace / group 中的租户前缀,最后把请求返回给租户。
- 罗列/监听 租户的资源:查询上游 K8S 所有此类 CR,KubeZoo 根据 group 匹配的租户前缀匹配本租户的所有此类资源;对于 response body,去除 namespace / group 中的租户前缀,最后把请求返回给租户。
- PUT:往 request url 的 group / namespace 和 request body 的 group / namespace 字段添加租户前缀,然后将请求转发至上游 K8s 完成资源更新;对于 response body,去除 group / namespace 中的租户前缀 ,最后把请求返回给租户。
- DELETE
- 删除某个资源:向 request url 的 group / namespace 字段正确的注入租户信息,然后将请求转发至上游 K8s 完成资源删除;对于 response body,去除 group / namespace 中的租户前缀,最后将请求返回给租户。
- 删除某些资源:在 request url 的 group / namespace 字段增加租户前缀,调整 label selector 涉及 namespace 相关的值,然后罗列符合要求的资源,对于属于本租户的资源,逐个删除;对于 response body,去除 group / namespace 中的租户前缀,最后把请求返回给租户。
对于 cluster scope 的 CR,结合上述逻辑易于推导,此处不再详述。
Cross Reference 资源
需要注意的是,同一租户的不同类型的资源 Spec 中的字段可能会存在资源引用的依赖情况,pvc 的 spec.volumeName 为对应的 pv,大体上可以将引用分为两类:
- namespace 内引用:例如 pod 引用 pvc / configmap / serviceaccount 等,此类上下游资源为 namespace scope 资源,且同属一个 namespace,因此不需要做任何处理。
- namespace 与 cluster 之间引用: pvc 引用 cluster scope pv,serviceaccount 引用 clusterrolebinding 等。对于此类的资源,需要准确理解其资源字段的含义,并在 KubeZoo 解析其 Body,完成资源名字的准确转换。 以 pvc 具体 case 为例,租户视角的 pvc:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
namespace: default
......
spec:
volumeName: pv-cb23c200-f249-11ea-9039-3497f65a8415
......
上游 K8s 视角的 pvc:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
namespace: foofoo-default
......
spec:
volumeName: foofoo-pv-cb23c200-f249-11ea-9039-3497f65a8415
......
常见涉及 namespace 和 cluster 之间交叉依赖的资源如下:
- clusterrole
- clusterrolebinding
- endpoint
- endpointslice
- pv
- pvc
- role
- rolebinding
- tokenreview
- volumeattachment
Non-resource 资源
除了上述核心资源以外,K8s 还有一部分 Non-resource API,主要包括监控、日志、Doc 等等。
对于 readyz / healthz / livez / version 等类型近 60 个 GET 类型的 API,这些 API 主要用于表示 master / etcd / poststarthook 各类 controller 的健康状况、版本信息等。因此对于此类 API KubeZoo 只需要将请求转发至下游 K8S 即可。
对于 /openapi/v2 API,KubeZoo 首先需要从上游 K8s 获取其支持的 openapi 资源,并从相关的资源过滤出租户的 CRD,然后合并原生 API 资源,最终返回给租户。
对于 /metrics API,这些 metrics 信息无法从租户粒度进行区分,且对于托管版本的 Serverless K8S 用户作用相对有限,因此暂不考虑支持详细的租户级别的 metrics。
对于 /logs API,由于其仅简单展示访问的审计信息,因此暂未支持详细的租户级别的 logs。从实现的角度可以在 KubeZoo 侧提供记录和审计能力,并将审计信息存储到 KubeZoo 的存储中。
小结
本文详细介绍了 KubeZoo 的核心理念和详细设计,从而保证了资源隔离的视图和逻辑的准确性;由于不同类型的资源存在一些差异,因此针对 namespace scope、cluster scope、custom 和 non-resource 等类型的资源做了分别的处理,既提供了隔离能力,又保证了准确性。